Tony Hernández-Pérez
Departamento de Biblioteconomía y Documentación
Universidad Carlos III de Madrid
Google Dataset Seach: beta. Disponible en: <https://toolbox.google.com/datasetsearch>. [Consulta: 16/10/2018].

El año 2018 está siendo muy entretenido en el mundo de la comunicación científica. En la primera parte del año se presentaron tres grandes bases de datos académicas 1Findr (de 1Science’s), Dimensions (de Digital Science) y Lens (de Cambia, una ONG australiana, que, además de artículos científicos, recoge incluso patentes). De repente, tres grandes bases de datos que aspiran a competir con la caja blanca, más bien negra, de Google Scholar y de Microsoft Academic. Y a la vuelta del verano, otras dos grandes sorpresas: el controvertido Plan S, una iniciativa de 12 de las más importantes agencias nacionales de financiación de la investigación en Europa. Un plan cuya intención es obligar a científicos e investigadores beneficiarios de fondos públicos de investigación para que en 2020 publiquen sus trabajos de forma inmediata solo en repositorios o revistas de acceso abierto, excluyendo incluso a las revistas híbridas. Una iniciativa que ha enfadado mucho, entre otros, a gran parte del sector editorial, que lo perciben como una gran amenaza. Y casi el mismo día, el 5 de septiembre de 2018, Google hizo público el lanzamiento de un nuevo producto: Google Dataset Search, cuyo objetivo es facilitar el acceso a los millones de datasets existentes en miles de repositorios en la web.
Google aspira a convertir su nuevo producto en «el Google Scholar de los datos»: el lugar en donde se pueden descubrir los datasets de calidad que sirvan a los investigadores, a los periodistas y a todos aquellos ciudadanos interesados en disponer de datos procedentes de fuentes de calidad. La hipótesis de trabajo de Google con el nuevo producto ha sido «Constrúyelo y vendrán» y no les ha faltado razón. El buscador, aún en fase beta y con muchas limitaciones, ha levantado muchas expectativas, seguramente, porque contribuye a resolver un grave problema: la dispersión de fuentes en las que se encuentran los conjuntos de datos más relevantes, tanto los producidos por los gobiernos (datos abiertos gubernamentales) como los producidos por los investigadores (datos abiertos de investigación).
En la actualidad, buscar datasets resulta extremadamente problemático, no sólo por los múltiples esquemas de metadatos que se utilizan para describir los datasets sino también por la multitud de repositorios de datos que existen. El directorio de repositorios de datos científicos más importante, el Registry of Research Data Repositories recoge ya más de 2.200 repositorios, 24 en España, algunos especializados en un tema, otros, como Zenodo, Mendeley o Figshare, más generalistas, en donde se puede encontrar casi cualquier tema. Nature recomienda depositar los datos que sirven de base a sus publicaciones en más de 50 repositorios diferentes. Y los repositorios de datos abiertos gubernamentales se encuentran igualmente dispersos. A veces, accesibles a través de un agregador y otras es necesario acudir a buscar en cada ayuntamiento, ministerio, o agencia gubernamental. Un caos para el usuario final, que finalmente no sabe en qué silo de datos buscar, que está obligado a usar una interfaz distinta para cada sitio y a obtener descripciones muy diversas de estos datasets.
Con su nuevo producto Google pretende contribuir a lo que ellos llaman un «fuerte ecosistema de datos abiertos» mediante el fomento de estándares abiertos de metadatos para describir los datasets publicados. En sus directrices, Google advierte que solo recolectará datasets de páginas web que contengan datos estructurados. Y recomienda el uso del tipo de contenido Datasets, del consorcio schema.org o estructuras equivalentes representadas en el Data Catalog Vocabulary (DCAT) del W3C, una buena noticia para muchos de los catálogos de datos abiertos gubernamentales, muchos utilizan este vocabulario, que podrán ver un aumento en el acceso a sus datasets si este producto de Google se populariza. La idea está clara, si el robot de Google descubre tus páginas web con datos estructurados que contengan datasets, los recogerá, si no… las tratará como una página más pero no entrará en su índice de datasets y tendrá más riesgo de perderse en la larga cola de resultados.
Google intenta, además, fomentar la cultura de la cita de datos, de forma similar a cómo citamos las publicaciones, para reconocer el mérito a aquellos que crean y publican datos. De hecho, en sus páginas de resultados ya se pueden apreciar mensajes del tipo «4 artículos académicos citan este conjunto de datos (Ver en Google Académico)», con lo que, al mismo tiempo, Google enlaza los datasets con los trabajos de investigación indexados en Google Scholar. Aún es pronto para saber si el sistema será reversible. ¿Desde los artículos se podrá acceder a los datasets indexados por Google? ¿Está Google pensando en contribuir a esta cultura añadiendo un botón para citar los datos de acuerdo al esquema de metadatos de Datacite u otro similar?
Google Dataset Search, a diferencia de su buscador general, trabajará exclusivamente con metadatos. Aun así, el reto no es menor: después de que el robot descubra los datasets deberá realizar una operación de «limpieza de datos», a pesar de los datos estructurados, es necesario normalizar fechas, detectar diferentes autores y asegurarse de que los metadatos están bien asignados porque estos metadatos suelen llegar con datos incompletos, erróneos o directamente omitidos; Google deberá identificar las réplicas, puesto que un mismo dataset puede estar depositado en varios repositorios al mismo tiempo, o ser un subconjunto de un dataset con un mayor nivel de agregación. A continuación, pasará la información por su gráfico de conocimiento (Knowledge Graph), la base de datos de conocimiento que utiliza Google para detectar entidades, lugares, etc. y entender el contexto de la página que está analizando. Y, finalmente, intentará enlazar el dataset con Google Scholar. Lo que construye Google es, pues, un gigantesco índice de metadatos limpios y enriquecidos que será la base de datos en la que busquemos los usuarios. Así, la calidad de la base de datos será mayor o menor en función de la calidad de los metadatos que asignen los proveedores de los datasets.
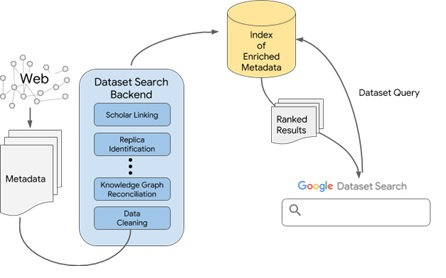
Esquema del funcionamiento de Google Dataset Search
Fuente: https://ai.googleblog.com/2018/09/building-google-dataset-search-and.html
El producto, como decíamos, está en fase beta. Google aún no sabe cómo buscamos los usuarios datasets y espera poder aprender del uso que hacemos del buscador para poder mejorarlo. Por ahora, no se saben los criterios con los que muestra el ranking de resultados, no se sabe si utiliza la fiabilidad de la fuente, el número de citas del dataset en Google Scholar, la fecha de actualización o de cobertura temporal o cualquier otro criterio. La interfaz de los resultados es muy mejorable: no ofrece ni siquiera los resultados aproximados a una búsqueda; las descripciones de los distintos datasets son muy dispares; apenas se muestran de tres a cinco resultados; no permite filtrados de casi ningún tipo, aunque parece que funciona el operador site: xxx.xx para limitar las búsquedas; no hay búsqueda avanzada ni ninguna ayuda de cómo buscar. Y, como en Google Scholar, por desgracia, no proporciona ninguna API (application programming interface). Y, por ahora, no resulta fácil encontrar un listado de los repositorios que están indexando, más allá de algunos de los grandes repositorios que de alguna forma están contribuyendo activamente al despegue de Google Dataset Search (NOAA, ICPSR, Dataverse…) cumpliendo con las directrices de Google para publicar datasets.
La mayor parte de los grandes repositorios, como Zenodo, Dryad o Figshare soportan y describen en JSON-LD sus datasets de acuerdo a schema.org. Sin embargo, muchos repositorios que han estado almacenando datasets de sus investigadores no trabajan aún con schema.org, por lo que, si se quiere aumentar la visibilidad de los datasets para luego intentar hacer un seguimiento de sus citas y de su uso, convendrá ir preparándose. En cualquier caso, para aquellos datasets a los que queramos dar visibilidad de forma inmediata y hasta la implementación de schema.org en nuestro repositorio, siempre se puede acudir, como hasta ahora, a registrar el dataset en algunos de los hubs o agregadores que sí lo tengan implementado, por ejemplo, en Datacite o en datos.gob.es para el caso de datos abiertos gubernamentales.
La aparición de Google Dataset Search produce sensaciones encontradas. Por un lado, puede ayudar a simplificar la búsqueda de datos abiertos, como ha ocurrido con Google Scholar. Siendo consciente de la importancia de los datos y, por fin, de los metadatos, está construyendo un producto o servicio capaz de conectarse a distintos repositorios, bibliotecas digitales, revistas y catálogos de datos de las administraciones y agencias gubernamentales para facilitar al usuario final la búsqueda de datos abiertos desde un único sitio. Por otro lado, el éxito del servicio significará una especie de punto único de acceso a todos los datos abiertos, una especie de jardín único y privado de Google, gratis, sí, pero privado, porque será Google el único que tendrá acceso a toda la información y los datos que ese punto único de acceso genere. Ahora que gracias a los identificadores persistentes vemos aparecer nuevas bases de datos de artículos científicos como Lens, Dimensions o 1Findr quizás también veamos aparecer otros buscadores de datasets alternativos. Ojalá aparezcan estas alternativas y ojalá que Google no deje morir su nuevo juguete, como tantos otros productos.

