Capítol 2 Una visió general
2.1 Introducció: una mica d’endreça
Per començar a treballar en la sessió d’avui, creeu primer un projecte anomenat Barris_BCN al directori on guardeu els vostres projectes. Imaginem que jo guardo tots els projectes en un directori que es diu /Documents i que tinc creat a la meva carpeta de Dropbox. Comenceu assegurant-vos que R està treballant en el directori on voleu crear el projecte:
getwd() # R està en un directori que no és el que jo vull (/Documents)
setwd("D:/Usuarios/vallbe/Dropbox/Documents/") # Estableixo el directori que vullPer fer-ho, heu de tenir instal·lada la llibreria ProjectTemplate. Començarem activant-la:
library(ProjectTemplate) # Activo la llibreria
create.project("Barris_BCN") # Creo el projecte
# Li dic a R que se situï dins del meu projecte:
setwd("D:/Usuarios/vallbe/Dropbox/Documents/Barris_BCN") 2.2 Importació de dades
Baixeu-vos la base de dades lloguer_barris.csv. Les dades corresponen als preus mitjans de lloguer d’habitatge dels barris de Barcelona els quatre trimestres de l’any 2015, segons dades de l’Ajuntament de Barcelona. Guardeu aquestes dades dins el directori del vostre projecte d’anàlisi, específicament a data/original_data/. Aquestes dades no les obriu mai. Feu-ne una altra còpia i guardeu-la a data/, que seran aquestes les que farem servir.
Aquestes dades no tenen format, són text pla, i l’única especificitat que tenen és que els seus valors estan separats per comes. D’aquí la seva extensió .csv, que vol dir comma-separated value. Aquest és un format amb què programes com el LibreOffice treballa amb molta comoditat. R també ho fa, i compta amb funcions bàsiques per poder obrir aquestes dades.
Per carregar les dades, farem servir la funció read.csv(). Fixeu-vos que per identificar l’arxiu de dades que volem obrir, a la funció li hem d’especificar la ruta per tal que trobi la base de dades adequada, és a dir, la ruta a partir del directori principal del vostre projecte. En aquest cas, com que estem dins del directori del nostre projecte, li diem que ha d’entrar a la subcarpeta data/i trobar-hi les dades lloguer_barris.csv. Finalment, amb l’argument sep="," li especifiquem que els valors, en aquestes dades, estan separats per comes. El fet de separar els valors per comes és una convenció; també podríem separar per punt i coma o per qualsevol altre símbol. En cas que fos un altre símbol, l’hauríem d’especificar a l’argument sep= de la funció read.csv(), entre cometes. Un altre argument que fem servir és `na.strings’, que especifica a R quin tipus de símbol indica que no hi ha dades. Aquest argument és extremament útil, atès que tradicionalment cada institució dedicada a la construcció de dades fa servir codis diferents per indicar l’absència de dades. En aquest cas, l’Ajuntament de Barcelona fa servir l’expressió “n.d.”, i per això ho indiquem així. El que farà aquest argument és que en les dades que obrim amb R totes les observacions que tinguin com a valor “n.d.” siguin convertides a “NA”, que és la forma nadiua de R per indicar absència de dades. Finalment, com que la base de dades serà un objecte, per carregar-les i que quedin a la memòria per tal que hi puguem treballar, les assignem a un nom que ens vagi bé, per exemple barris:
barris <- read.csv(
"data/lloguer_barris.csv",
sep=",",
na.strings = "n.d.",
fileEncoding = "latin1"
)Com que les bases de dades amb què treballem sovint tenen força observacions (diguem que més de 50 ja és un nombre elevat d’observacions) i unes quantes variables, no podem executar directament barris per veure les dades, ja que no és gaire pràctic. En canvi, començarem observant les primeres observacions per fer-nos una idea de l’estructura de les dades, amb les funcions head(), tail() i dim():
head(barris) # Les 6 primerers observacions## districte barri T1 T2 T3 T4
## 1 1 Raval 601.31 598.91 654 644.73
## 2 1 Barri Gòtic 756.68 771.13 773 831.13
## 3 1 Barceloneta 581.34 598.16 630 601.38
## 4 1 Sant Pere Santa Caterina i la Ribera 697.16 708.03 729 751.60
## 5 2 Fort Pienc 753.76 770.13 753 792.53
## 6 2 Sagrada Família 679.03 704.44 739 726.93tail(barris) # Les 6 darreres observacions## districte barri T1 T2 T3 T4
## 68 10 Poblenou 682.84 711.46 764 773.52
## 69 10 Diagonal Mar i el Front Marítim 914.75 981.86 1023 1211.01
## 70 10 Besòs i el Maresme 512.89 505.97 516 492.10
## 71 10 Provençals del Poblenou 612.11 670.38 679 685.35
## 72 10 Sant Martí de Provençals 662.25 697.32 672 666.84
## 73 10 Verneda i la Pau 609.22 595.42 633 602.19dim(barris) # Quantes files i quantes columnes té la base de dades## [1] 73 62.3 Treballar amb altres formats de dades
També les podem importar directament des del format excel o altres formats, però
mentre que amb dades sense format (escrites en “text pla”) com .txt o .csv ho
podem fer amb una de les llibreries bàsiques que ja vénen amb R per defecte, per
obrir un arxiu .xls, xlsx, .sav (SPSS), .por (SPSS), .dat (STATA), etc. hem
d’instal·lar llibreries específiques com foreign, memisc, xlsx i Hmisc.
Per exemple, si volem obrir un arxiu en format .sav (SPSS), primer haurem d’instal·lar la llibreria foreign, carregar-la i fer servir la seva funció read.spss(). Ho provarem amb un arxiu del CIS corresponent a l’estudi \(2799\) (Baròmetre d’abril de 2009), que tenim guardat al subdirectori /data:
library(foreign)
datacis <- read.spss("data/es2799.sav")## re-encoding from CP1252class(datacis)## [1] "list"Com podeu veure, si llegim les dades sense especificar res més, R ens crea una llista on cada variable és un element diferent. Si el que volem és un data frame, ho haurem d’especificar amb un argument de la funció:
datacis <- read.spss("data/es2799.sav", to.data.frame = TRUE)## re-encoding from CP1252dim(datacis)## [1] 3255 231datacis[1:10, 1:12]## CUES A1 CCAA PROV MUN TAMUNI AREA DISTR SECCION ENTREV P0 P0A
## 1 2770 279902770 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 2 2771 279902771 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 3 2772 279902772 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 4 2773 279902773 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 5 2774 279902774 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 6 2775 279902775 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 7 2776 279902776 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 8 2777 279902777 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 9 2778 279902778 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0
## 10 2779 279902779 País Vasco Vizcaya 20 100001 a 400000 habitantes 0 0 0 0 Española 0names(datacis)## [1] "CUES" "A1" "CCAA" "PROV" "MUN" "TAMUNI" "AREA" "DISTR" "SECCION" "ENTREV"
## [11] "P0" "P0A" "P0B" "P101" "P102" "P103" "P104" "P2" "P3" "P401"
## [21] "P402" "P403" "P404" "P405" "P406" "P407" "P408" "P409" "P410" "P5"
## [31] "P6" "P701" "P702" "P703" "P704" "P705" "P706" "P707" "P708" "P709"
## [41] "P710" "P8" "P9" "P1001" "P1002" "P1003" "P1004" "P11" "P12" "P1301"
## [51] "P1302" "P1303" "P1304" "P1305" "P1306" "P1307" "P1308" "P1309" "P1310" "P14"
## [61] "P15" "P16" "P1701" "P1702" "P1703" "P1704" "P1705" "P1706" "P1707" "P1708"
## [71] "P1709" "P1710" "P18" "P1901" "P1902" "P1903" "P1904" "P1905" "P1906" "P1907"
## [81] "P1908" "P1909" "P1910" "P20" "P2101" "P2102" "P2103" "P2104" "P2105" "P2106"
## [91] "P2107" "P2108" "P2109" "P2110" "P2201" "P2202" "P2203" "P2204" "P2205" "P2206"
## [101] "P2207" "P2208" "P2209" "P23" "P24" "P2501" "P2502" "P2503" "P2504" "P2505"
## [111] "P2506" "P2507" "P2508" "P2509" "P2510" "P2601" "P2602" "P2603" "P2604" "P2605"
## [121] "P2606" "P2607" "P2608" "P2609" "P2610" "P2701" "P2702" "P2703" "P2704" "P2705"
## [131] "P2706" "P2707" "P2708" "P2709" "P2801" "P2802" "P2803" "P2804" "P2805" "P2806"
## [141] "P2807" "P2808" "P2809" "P29" "P30" "P31" "P32" "P32A" "P3301" "p3302"
## [151] "P3401" "P3402" "P3501" "P3502" "P3503" "P3504" "P3505" "P3506" "P3601" "P3602"
## [161] "P3603" "P3604" "P3605" "P3606" "P37" "P38" "P39" "P40" "P41" "P4201"
## [171] "P4202" "P43" "P4401" "P4402" "P4403" "P4404" "P4405" "P4406" "P4407" "P4408"
## [181] "P4409" "P4410" "P45" "P45A" "P45B" "P46" "P47" "P48" "P49" "P50"
## [191] "P51" "P52" "P53" "P54" "P55" "P55A" "P56" "P56A" "P57" "P58"
## [201] "P59" "P60" "P60A" "P61" "P62" "P63" "P64" "P65" "P6601" "P6602"
## [211] "P6603" "P6604" "P6701" "P6702" "P6703" "P6704" "P6705" "P6801" "P6802" "P6803"
## [221] "P6804" "P6805" "P69" "P70" "P71" "FINAL" "ESTUDIOS" "OCUPA" "CONDICION" "ESTATUS"
## [231] "PESO"2.4 Nivells de mesura
R té bàsicament quatre tipus de nivells de mesura. Per conèixer a quin tipus de mesura correspon una variable concreta, farem servir la funció class():
class(barris$T1)## [1] "numeric"En aquest cas obtenim que la variable T1 és numèrica. (Una variant de les numèriques és integer, que correspon a variables que contenen només nombres enters.)
Les variables categòriques (de dues o més categories) poden ser anomenades factor o character. La difèrencia entre les dues és l’existència i el reconeixement de les categories (levels) en el cas dels factor. Per exemple, fent servir la base de dades del CIS que hem carregat abans podem saber la classe de la variable CCAA:
class(datacis$CCAA)## [1] "factor"Si volem saber quines categories té aquesta variable:
levels(datacis$CCAA)## [1] "Andalucía" "Aragón" "Asturias (Principado de)"
## [4] "Baleares (Islas)" "Canarias" "Cantabria"
## [7] "Castilla La Mancha" "Castilla y León" "Cataluña"
## [10] "Comunidad Valenciana" "Extremadura" "Galicia"
## [13] "Madrid (Comunidad de)" "Murcia (Región de)" "Navarra (Comunidad Foral de)"
## [16] "País Vasco" "Rioja (La)"Típicament, una variable en què cada categoria conté més d’una observació (Home/Dona, CCAA, etc.) hauria de ser un factor, mentre que una variable com CUES (l’identificador de qüestionari) pot ser perfectament una variable character, ja que cada observació té un valor diferent. Per forçar una variable d’un nivell de mesura a un altre (s’ha d’anar molt amb compte), cada nivell de mesura té la seva funció específica. Per exemple, per convertir el número de qüestionari en una variable en un character:
class(datacis$CUES) # És numèrica## [1] "numeric"datacis$CUES.c <- as.character(datacis$CUES) # Creem una variable NOVA
class(datacis$CUES.c) # Mirem que la conversió s'ha fet bé## [1] "character"Fixeu-vos que ara els valors de les dues variables són una mica diferents: a la character els valors ara estan entre cometes:
datacis$CUES[1:10]## [1] 2770 2771 2772 2773 2774 2775 2776 2777 2778 2779datacis$CUES.c[1:10]## [1] "2770" "2771" "2772" "2773" "2774" "2775" "2776" "2777" "2778" "2779"2.5 Recodificació de variables
Un cop hem obert i explorat les nostres dades, és ben probable que no tinguem les variables en el format que més ens interessa per analitzar-les, representar-les o descriure-les. Per exemple, si volem presentar una taula mostrant la distribució dels preus de lloguer de la nostra base de dades, probablement necessitarem agrupar-les en diversos trams o intèrvals. El procés de canviar els continguts o estructura d’una variable es coneix com a recodificació. La recodificació es pot haver de produir en múltiples escenaris, però el més habitual és (1) haver de dividir una variable contínua (i.e., numèrica) en intèrvals, pel que de fet la convertim en una categòrica, (2) necessitar reduir el nombre de categories d’una variables categòrica ja existent, o (3) transformar matemàticament una variable contínua.
2.5.1 De variables contínues a categòriques
Per il·lustrar el primer dels casos, demanem una freqüència de la variable T1 de la base de dades barris, que indica el lloguer mitjà de cada barri durant el primer trimestre del 2015. Per demanar aquesta taula de freqüència farem servir la funció table().
table(barris$T1)##
## 303.8 383.62 401.17 433.81 455.96 461.89 469.83 485.74 492.49 504.27 505.02 512.89 515.49 521.06 543.33
## 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## 545.86 561.58 576.44 578.76 581.34 585.54 585.98 595.43 601.06 601.31 606.48 608.87 609.22 612.11 614.15
## 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## 615.46 616.05 618.57 619.16 621.71 626.23 653.16 662.25 665.89 673.2 679.03 682.84 697.16 701.69 707.17
## 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## 722.23 727.99 728.25 733.81 740 740.41 753.76 756.68 758.44 766.18 777.25 822.36 859.64 914.75 917.13
## 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## 954 957.55 1088.66 1093.14 1250.83 1335.63 1335.71
## 1 1 1 1 1 1 1El que obtenim, però, és una taula molt poc informativa, ja que és una llista de valors de lloguer i, a cadascun d’ells, li correspon una freqüència de 1, perquè cada barri té un lloguer mitjà diferent. Per això necessitem fer intèrvals. Per fer-ho, hi ha múltiples possibilitats. Una d’elles és deixar que R divideixi la variable en tants talls com nosaltres li indiquem, creant una variable categòrica. Per exemple, si volem la variable T1 dividida en 4 categories, podem fer servir la funció cut():
barris$T1_rec <- cut(barris$T1, breaks = 4) # Especifiquem el nombre de talls
table(barris$T1_rec)##
## (303,562] (562,820] (820,1.08e+03] (1.08e+03,1.34e+03]
## 17 39 6 5Fixeu-vos en la lògica de la recodificació expressada en R. Primer hem creat una variable nova, que serà afegida a la base de dades: barris$T1_rec. Això és una recomanació general: sempre que vulguem canviar alguna variable fem-ho creant-ne una de nova i mai planxant la variable existent. Segon, hem especificat que el nombre de talls ha de ser 4, i amb aquesta informació, R ha tallat la variable en 4 intèrvals iguals. Podríem fins i tot introduir noms per a les categories indicant el nivell de lloguer (baix, baix-mig, mig-alt, alt) creades per R, com farem a continuació. En qualsevol cas, després de fer la recodificació, especifiquem que aquesta nova variable és categòrica (un factor, en llenguatge R), i després en fem la taula de freqüències.
barris$T1_rec <- cut(
barris$T1,
breaks = 4,
labels = c("Baix", "Baix-Mig", "Mig-Alt", "Alt")
)
barris$T1_rec <- as.factor(barris$T1_rec)
class(barris$T1_rec) # Això ens confirma que hem creat una categòrica ## [1] "factor"table(barris$T1_rec) # Creem la taula de freqüències##
## Baix Baix-Mig Mig-Alt Alt
## 17 39 6 5head(barris) # La variable apareix afegida com a columna a la base de dades## districte barri T1 T2 T3 T4 T1_rec
## 1 1 Raval 601.31 598.91 654 644.73 Baix-Mig
## 2 1 Barri Gòtic 756.68 771.13 773 831.13 Baix-Mig
## 3 1 Barceloneta 581.34 598.16 630 601.38 Baix-Mig
## 4 1 Sant Pere Santa Caterina i la Ribera 697.16 708.03 729 751.60 Baix-Mig
## 5 2 Fort Pienc 753.76 770.13 753 792.53 Baix-Mig
## 6 2 Sagrada Família 679.03 704.44 739 726.93 Baix-MigEn cas que no volguéssim que els intèrvals fossin exactament iguals, fins i tot podríem haver especificat els punts de tall concrets on volem que la funció cut() faci els talls. Per exemple, imaginem que volem intèrvals que tinguin aproximadament 250 euros de diferència. Aleshores, com que sabem que la variable es distribueix entre els 303 i els 1336 euros, establirem talls en els punts 550, 800, 950, 1200, 1450. Fixeu-vos també que com que especifiquem 5 talls, també especificarem 5 etiquetes per als talls.
barris$T1_rec <- cut(
barris$T1,
breaks = c(300, 550, 800, 950, 1200, 1450),
labels=c("Baix", "Baix-Mig", "Mig", "Mig-Alt", "Alt")
)
table(barris$T1_rec)##
## Baix Baix-Mig Mig Mig-Alt Alt
## 16 40 4 4 32.5.2 De contínues a dicotòmiques
El procés de reducció màxim d’una variable contínua és la seva transformació en una de dicotòmica, és a dir, en una variable que només prengui dos valors (típicament \(0\) i \(1\)). Imaginem que ens interessa que la variable dels lloguers dels barris de Barcelona només tingui dos valors: Alt (\(1\)) i Baix (\(0\)). Per fer-ho, és recomanable buscar un criteri que permeti establir què vol dir un lloguer alt i un de baix. Un criteri força utilitzat és el lloguer mitjà (o medià, en funció de la distribució de la variable), de manera que aquells barris que estan per sobre de la mitjana (o mediana) els correspongui un lloguer alt i que estan per sota un de baix.
Per fer-ho, farem servir una funció molt útil de R que serveix exactament per dividir els valors d’una variable en dues parts a partir d’un criteri que nosaltres especifiquem. Aquesta funció és ifelse() i a continuació la farem servir fent servir el criteri de la mitjana:
barris$T1_dic <- ifelse(barris$T1 > mean(barris$T1, na.rm=TRUE), 1, 0)
barris$T1_dic <- as.factor(barris$T1_dic) # Convertim en un factor
table(barris$T1_dic)##
## 0 1
## 40 27Si volem, en comptes dels valors genèrics \(0\) i \(1\) podem especificar directament les etiquetes que volem que tingui cada categoria:
barris$T1_dic <- ifelse(barris$T1 > mean(barris$T1,na.rm=TRUE), "Alt", "Baix")
barris$T1_dic <- as.factor(barris$T1_dic) # Convertim en un factor
table(barris$T1_dic)##
## Alt Baix
## 27 402.5.3 De variables categòriques a categòriques
2.5.3.1 Reducció de categories
De vegades, les variables categòriques existents en una base de dades no ens van bé. Un cas típic és que sovint les variables originals tenen massa categories i a nosaltres ens n’interessa una amb menys. Per exemple, imaginem que necessitem que la variable T1_rec que hem creat abans tingui només tres categories (baix, mig i alt) en comptes de les cinc que té ara. Per fer-ho, haurem d’especificar quins valors de l’antiga variable corresponen a la nova, que afegirem a la base de dades, pas per pas:
barris$T1_rec_3[barris$T1_rec == "Baix"] <- "Baix"
barris$T1_rec_3[
barris$T1_rec == "Baix-Mig" |
barris$T1_rec == "Mig"|
barris$T1_rec == "Mig-Alt"
] <- "Mig"
barris$T1_rec_3[barris$T1_rec == "Alt"] <- "Alt"
table(barris$T1_rec_3)##
## Alt Baix Mig
## 3 16 48D’aquest codi hi ha unes quantes coses que són noves i que cal comentar. Primer, fixem-nos en la primera línia de codi. Com en el cas anterior de recodificació, el primer que fem és establir una nova variable afegint-la a la base de dades existent (barris$T1_rec_3). A continuació obrim claudàtors ([]) i a dins hi especifiquem el valor de la variable antiga que volem recofificar. Finalment, a aquesta combinació (que es pot llegir com “quan la variable antiga tingui el valor Baix, a la variable nova li correspon…”) li assignem el valor que volem que tingui la variable nova. És més interessant, però, la porció de codi del mig, que ocupa tres línies. En aquest cas, estem especificant que allà on la variable antiga prenia els valors “Baix-Mig”, “Mig” o “Mig-Alt”, a la variable nova li correspondrà el valor “Mig”. El criteri adversatiu o, que indica intersecció, en R es representa amb una barra vertical |, mentre que el criteri d’unió i està representat pel símbol &.
Fixeu-vos que si ara fem una taula de freqüències de la nova variable, les seves categories queden ordenades alfabèticament. Si volem que estiguin ordenades per la seva lògica conceptual (és a dir, de manera ordinal de baix a alt o a la inversa), ho podem fer un cop creada la nova variable tot especificant l’ordre dels nivells de la variable (levels):
barris$T1_rec_3 <- factor(
barris$T1_rec_3,
levels = c("Alt", "Mig", "Baix")
)
table(barris$T1_rec_3)##
## Alt Mig Baix
## 3 48 16Finalment, imagineu que teniu aquesta darrera variable feta però que heu de publicar un article en anglès i, per tant, us convé que les categories estiguin no en català sinó en anglès. Per fer-ho, crearem una altra variable idèntica a aquesta però amb un canvi d’etiquetes (labels):
barris$T1_rec_3_en <- factor(
barris$T1_rec_3,
labels = c("High", "Medium", "Low")
)
table(barris$T1_rec_3_en)##
## High Medium Low
## 3 48 16Cal no confondre levels (els nivells o categories d’una variable categòrica) amb labels (les etiquetes que prenen aquestes categories o nivells). Les variables T1_rec_3i la seva versió en anglès T1_rec_3_en tenen exactament els mateixos nivells (levels) però en canvi etiquetes (labels) diferents.
2.5.4 De variables categòriques a dicotòmiques
També podem fer servir la funció ifelse() per reduir una variable categòrica a dicotòmica. Per exemple, si volguéssim agrupar les categories de la variable T1_rec en només dues: lloguer alt (que contindria els barris amb lloguer Alt i Mig-alt a la variable T1_rec) i lloguer mig o baix (que contindria la resta de categories):
barris$T1_dic2 <- ifelse(
barris$T1_rec == "Alt" | barris$T1_rec == "Mig-Alt",
"lloguer alt",
"lloguer mig o baix"
)
barris$T1_dic2 <- as.factor(barris$T1_dic2)
table(barris$T1_dic2)##
## lloguer alt lloguer mig o baix
## 7 60Fixem-nos en el funcionament de la funció ifelse(). Primer, com sempre, hem creat una nova variable T1_dic. L’expressió ifelse fa referència a un procediment molt habitual en programació (i que ve de l’anglès) que estableix primer una condició (en anglès, if) i aleshores què passa amb tot allò que no compleix la condició (else). És a dir, en aquest cas hem expressat que si passa que un valor de la variable T1 és més gran que la mitjana de la variable (expressat amb l’operador >), aleshores li correspon el valor “Alt” en la nova variable. I que tots aquells valors que no ho compleixen tindran el valor “Baix”. Després, com sempre, convertim la variable en un factor i en fem la taula de freqüències.
2.6 Càlcul de noves variables
Hi ha una tercera modalitat de recodificació que, en realitat, és una transformació d’una variable numèrica a partir de l’aplicació d’alguna operació matemàtica sobre tots els seus valors. Per exemple, sovint en models de regressió que inclouen la variable edat, aquesta variable s’ha d’incloure tant en la seva escala natural com elevada al quadrat. Un altre exemple de transformació necessària és l’escala logarítmica, que serveix per equilibrar la distribució de variables (com ara la població dels municipis de Catalunya) que tenen distribucions molt esbiaixades i no permeten un tractament estadístic adequat. Aquesta transformació és molt senzilla. Imaginem que, per la raó que sigui, necessitem la variable T1 al quadrat, en la seva arrel quadrada i, també, la seva versió a escala logarítmica, per mostrar transformacions força habituals:
barris$T1_quadrat <- (barris$T1) ^ 2 # quadrat
barris$T1_quadrat <- sqrt(barris$T1) # arrel quadrada
barris$T1_log <- log(barris$T1) # logaritme natural
head(barris)## districte barri T1 T2 T3 T4 T1_rec T1_dic T1_rec_3 T1_rec_3_en
## 1 1 Raval 601.31 598.91 654 644.73 Baix-Mig Baix Mig Medium
## 2 1 Barri Gòtic 756.68 771.13 773 831.13 Baix-Mig Alt Mig Medium
## 3 1 Barceloneta 581.34 598.16 630 601.38 Baix-Mig Baix Mig Medium
## 4 1 Sant Pere Santa Caterina i la Ribera 697.16 708.03 729 751.60 Baix-Mig Alt Mig Medium
## 5 2 Fort Pienc 753.76 770.13 753 792.53 Baix-Mig Alt Mig Medium
## 6 2 Sagrada Família 679.03 704.44 739 726.93 Baix-Mig Alt Mig Medium
## T1_dic2 T1_quadrat T1_log
## 1 lloguer mig o baix 24.52162 6.399111
## 2 lloguer mig o baix 27.50782 6.628940
## 3 lloguer mig o baix 24.11099 6.365336
## 4 lloguer mig o baix 26.40379 6.547015
## 5 lloguer mig o baix 27.45469 6.625074
## 6 lloguer mig o baix 26.05820 6.5206652.7 Gràfics per representar freqüències
Un dels trets més extraordinaris de R és la seva capacitat per generar gràfics d’alta qualitat, que es produeix per la seva extrema flexibilitat, que significa que quan creem un gràfic podem especificar tots els seus paràmetres. Absolutament tots. A continuació veurem alguns exemples de gràfics habituals. Començarem amb gràfics que sovint es fan servir per representar freqüències: els gràfics de barres i els de punts.
2.7.1 Gràfics de barres
Els gràfics de barres representen exactament el mateix que una taula de freqüència: el recompte d’una variable categòrica. Així, si volem representar les freqüències de la primera variable categòrica que hem creat a partir dels lloguers dels barris crearem primer una taula de freqüències i després farem servir la funció barplot() per crear el gràfic:
t <- table(barris$T1_rec)
barplot(t)
El resultat del gràfic sense especificar res més respecta prou bé els principis de sobrietat, cura i equilibri que ha de tenir un gràfic. Potser hi falta una mica d’informació, com ara què volen dir els eixos, o un títol del gràfic, si és que no l’hem d’afegir a un article on ja pot contenir un peu de figura. Per afegir aquesta informació de context, afegirem arguments a la funció principal:
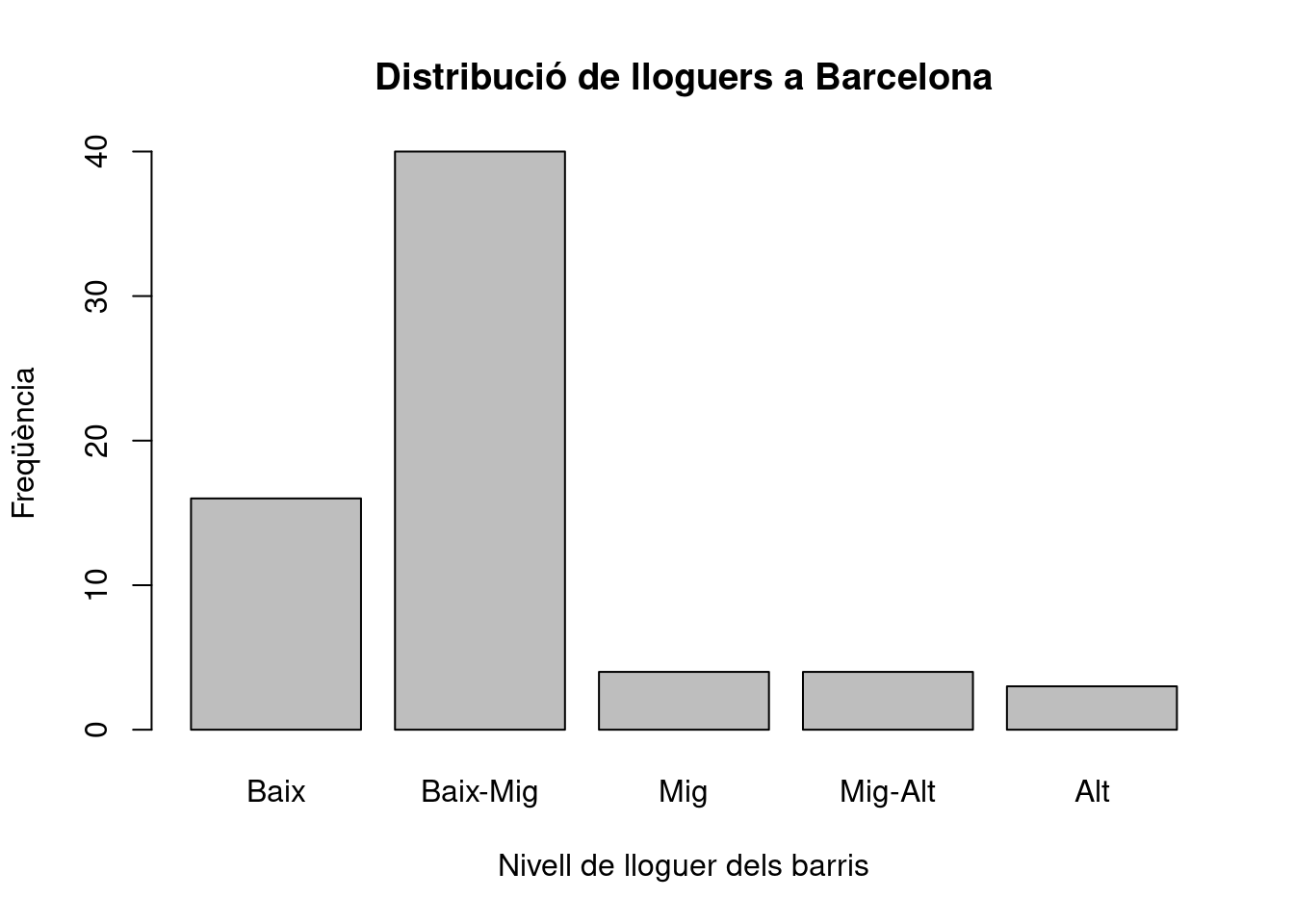
barplot(t,
xlab = "Nivell de lloguer dels barris", # Etiqueta eix X
ylab = "Freqüència", # Etiqueta eix Y
main = "Distribució de lloguers a Barcelona"
) 
2.7.2 Gràfics de caixes
En cas que vulguem obtenir una visualització més precisa de la distribució del lloguer mitjà, en què puguem identificar-ne alguns indicadors sintètics de forma gràfics, optarem pels gràfics de caixa (boxplot). El gràfic de caixa (boxplot o box-and-whisker plot) proporciona informació molt valuosa sobre la distribució d’una variable. En concret, ens marca els punts dels quartils primer (Q1), segon (Q2 o mediana) i tercer (Q3) d’una variable. Aquests tres quartils queden delimitats per la caixa del diagrama. A més, les extensions del gràfic (bigotis o whiskers) marquen fins a quin punt la resta de valors es troben molt o poc propers als quartils centrals. Els extrems dels bigotis, doncs, marquen els límits de les dades que es troben fins a 1.5 vegades el rang interquartílic (IQR\(=Q3-Q1\)). En aquest cas, al codi bàsic (que seria boxplot(barris$T1)) hi afegim un argument per tal que el gràfic sigui mostrat de forma horitzontal, així com una etiqueta a l’eix x.
boxplot(
barris$T1,
horizontal = TRUE,
xlab = "Lloguer mitjà"
)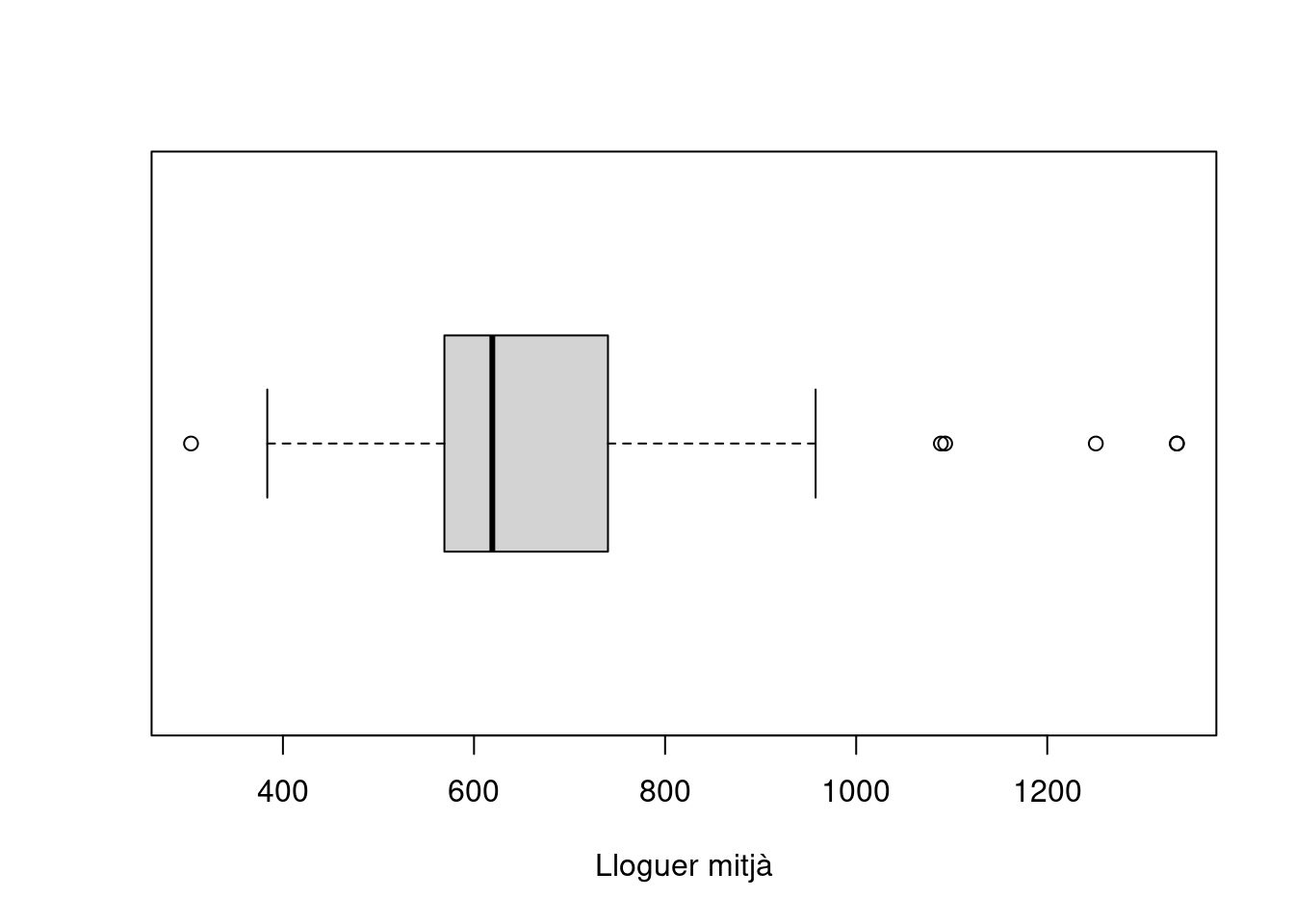
El gràfic és efectiu i net, i ens mostra que el primer trimestre de 2015 el lloguer medià (la barra vertical dins de la caixa) era lleugerament superior als 600 euros i que el 50% dels casos (els límits de la caixa són el quartil 25 i el 75) es troben entre una mica menys de 600 i una mica menys de 800 euros.
Podem condicionar aquesta freqüència al valor d’altres variables categòriques. Per exemple, si volem conèixer la distribució del lloguer per barris dins de cada districte per poder treure conclusions sobre el grau d’homogeneïtat econòmica dels districtes, podem obtenir un boxplot separat per districtes:
boxplot(
barris$T1~barris$districte,
horizontal = FALSE,
xlab = "Districte",
ylab = "Lloguer mitjà"
)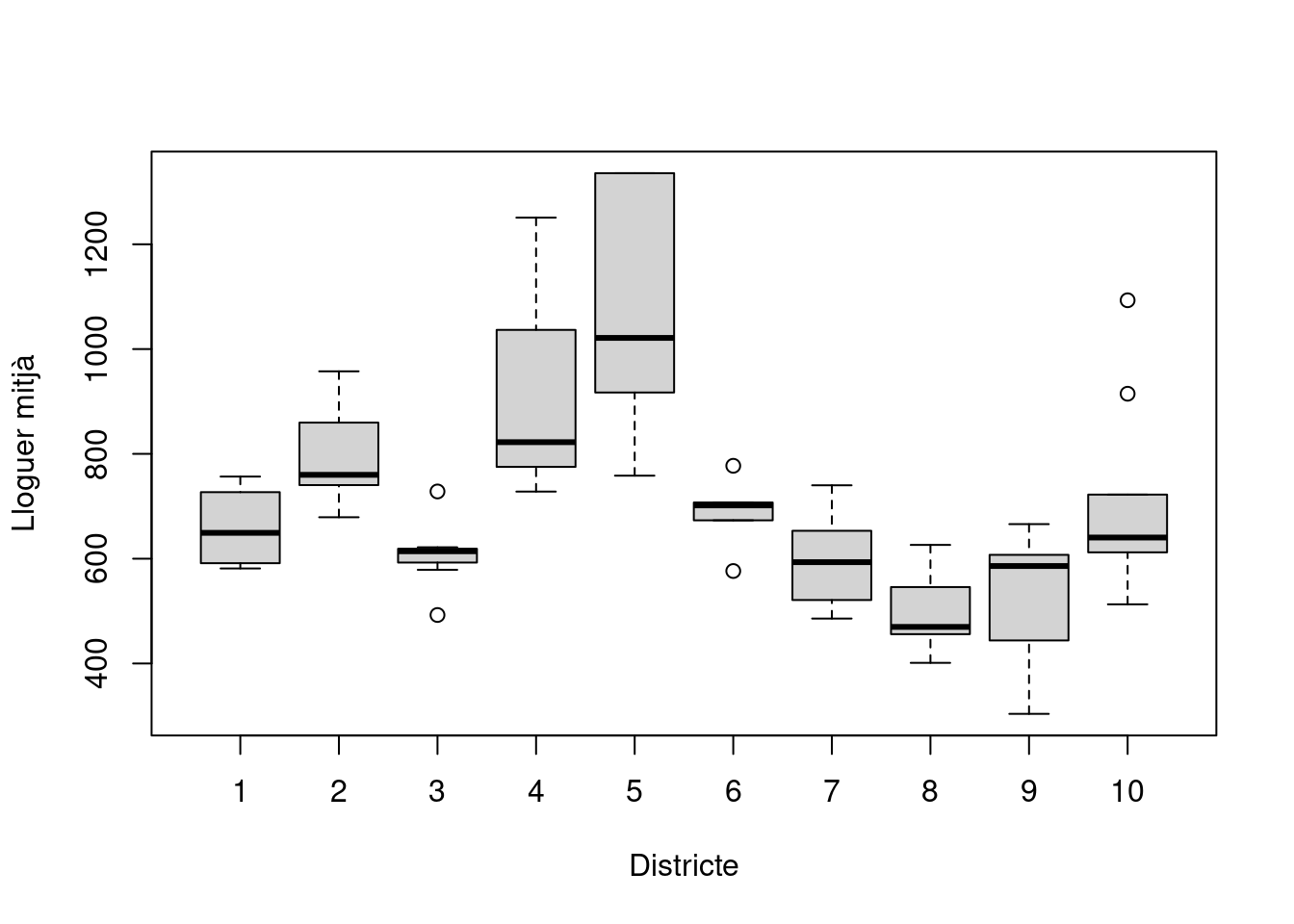
El gràfic ens indica que el districte amb el lloguer medià més alt (el número 5, Sarrià-Sant Gervasi), és també el que presenta una més gran variació entre els preus de lloguer dels seus barris. En canvi, districtes com el 3 (Sants-Monjuïc) o el 6 (Gràcia) no presenten tanta variació, ja que tenen les caixes molt més estretes.
2.7.3 Histogrames
Finalment, la distribució d’una variable contínua també es pot observar a través d’un histograma, a través de la funció hist(). La seva representació per defecte ofereix el següent resultat:
hist(barris$T1)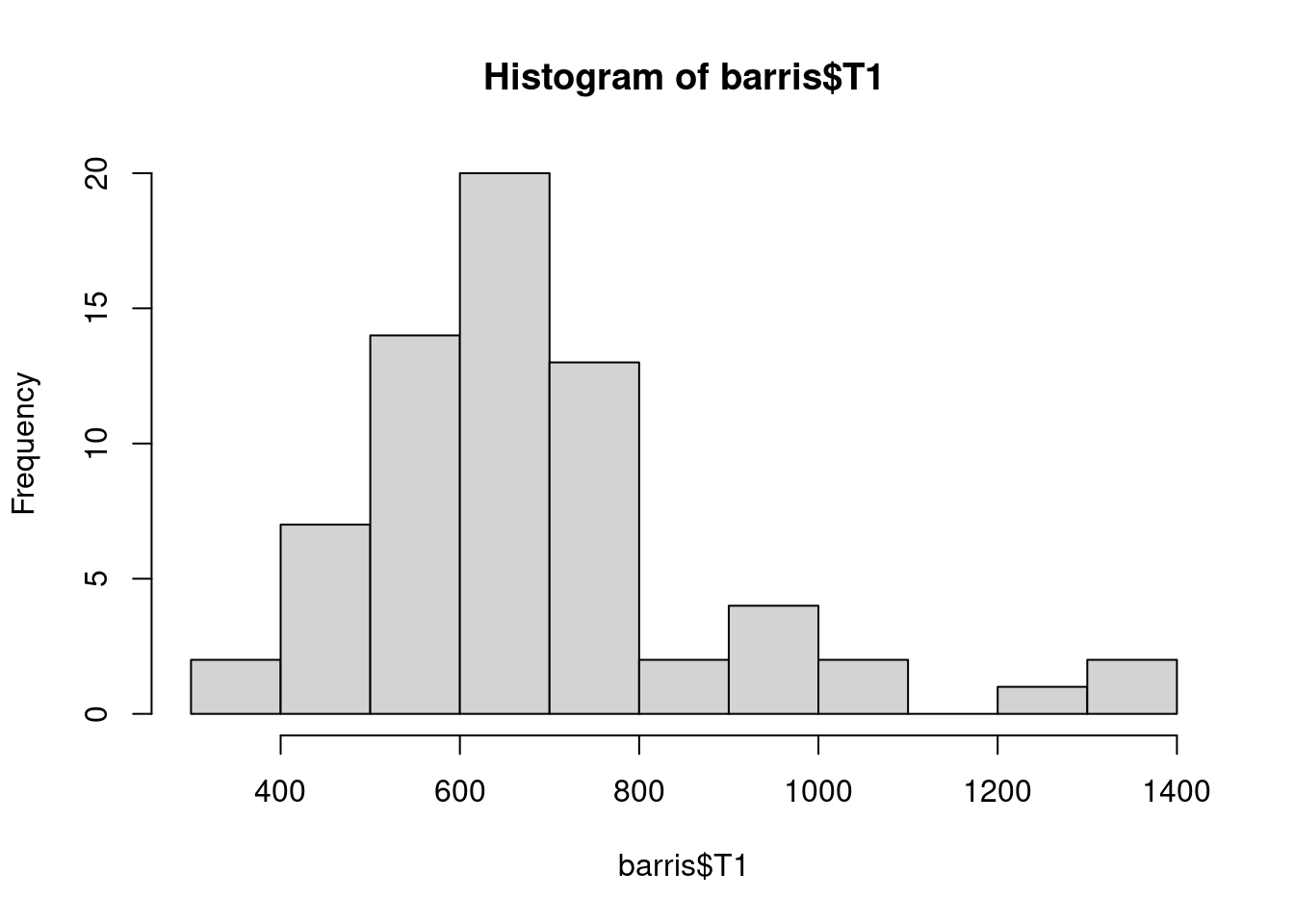
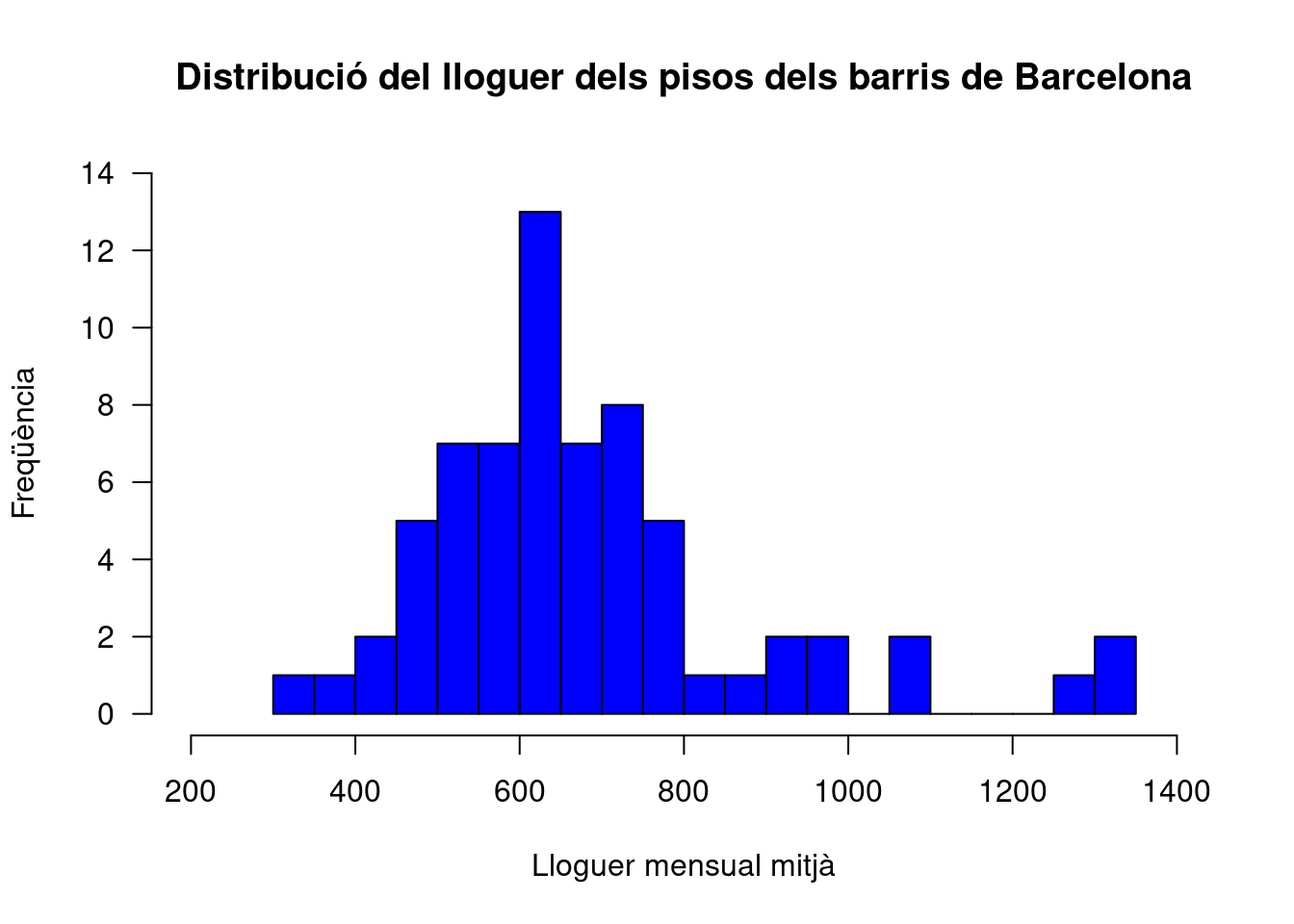
En el següent exemple mostrem com podem canviar un bon grup de paràmetres de l’histograma, que pot servir per exemple per a la resta de gràfics de R (que comparteixen en bona mesura els mateixos paràmetres). Primer, amb els arguments main, xlab i ylab especifiquem les etiquetes que donen context al nostre gràfic. A continuació, l’argument col especifica el color de l’interior de les barres de l’histograma. Per la seva banda, fixem-nos que aquest histograma té més barres que l’anterior. Això és així perquè hem especificat que les barres representessin un total de 15 talls (breaks=15). Finalment, també hem retocat els eixos del gràfic. Primer, hem establert els límits dels eixos x i y, i finalment, amb las hem establert que les marques numèriques de l’eix y apareguin en vertical. Com veiem, doncs, ho podem canviar tot, d’un gràfic, per tal que s’ajusti a les nostres necessitats.
hist(
barris$T1,
main = "Distribució del lloguer dels pisos dels barris de Barcelona",
xlab = "Lloguer mensual mitjà",
ylab = "Freqüència",
col = "blue",
breaks = 15,
xlim = c(200, 1400),
ylim = c(0, 14),
las = 1
)
2.7.4 Gràfics de punts
Si en comptes d’un gràfic de barres preferim l’elegància dels gràfics de punts per representar la distribució sencera de la variable, la funció dotchart() ens permetrà obtenir-ne un:
dotchart(barris$T1)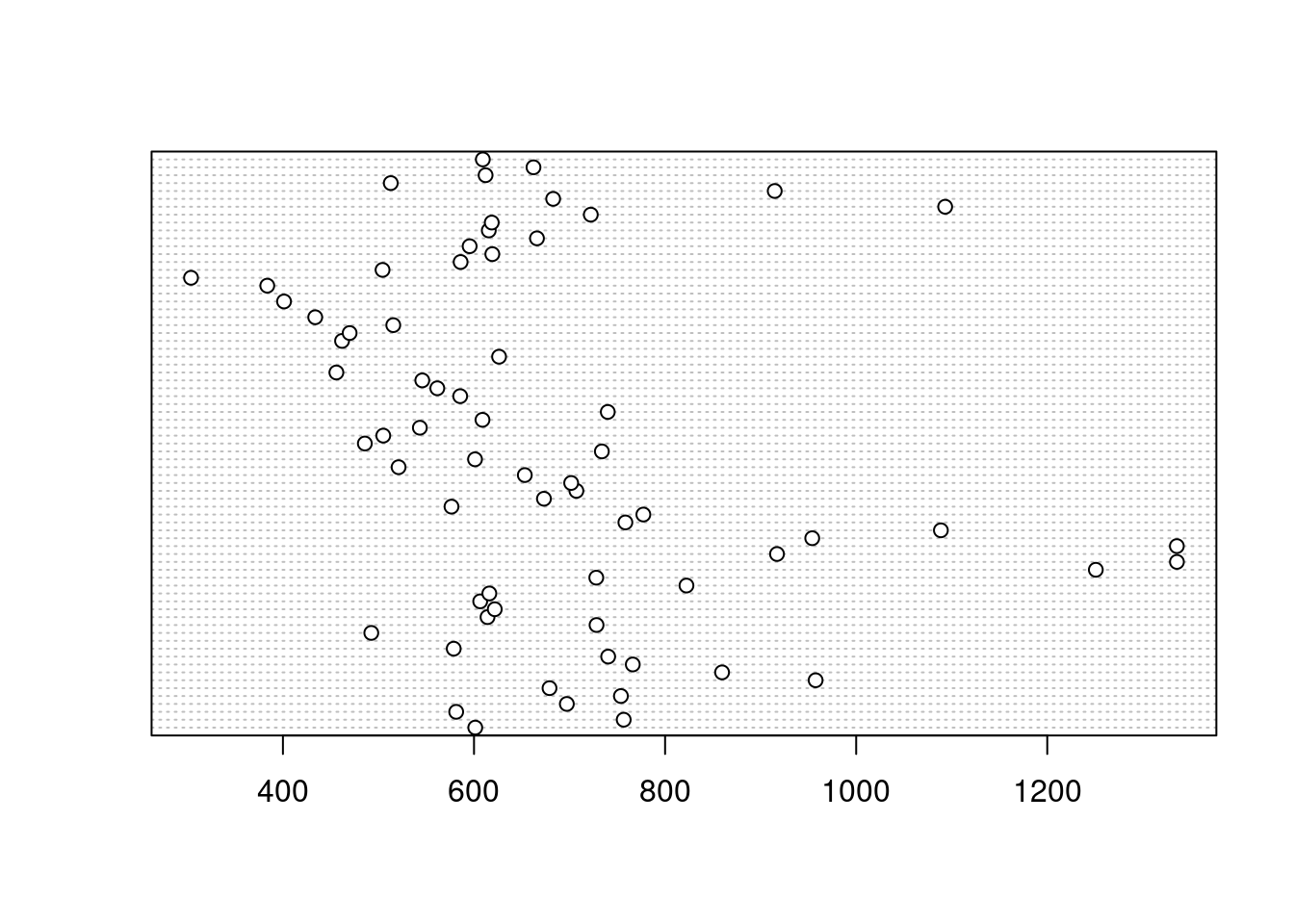
En aquest cas, el resultat per defecte no és gens satisfactori, per diverses raons. Primer, perquè no podem determinar a quin barri correspon cada nivell de lloguer. Segon, perquè els punts estan desordenats i la visualització no és efectiva.
Resoldrem aquests problemes un per un. Per introduir els noms dels barris, farem servir l’argument labels i direm que les etiquetes han de correspondre amb la variable barri de la base de dades, que conté el nom de cada barri. A més, com que el nombre de barris és elevat, reduïrem la mida de la lletra dels noms de barri (cex = 0.3) perquè no ens ocupi massa lloc. Finalment, hem afegit una etiqueta a l’eix x per identificar la variable que estem mostrant.
dotchart(
barris$T1,
labels = barris$barri,
cex = 0.3,
xlab="Lloguer mensual mitjà"
)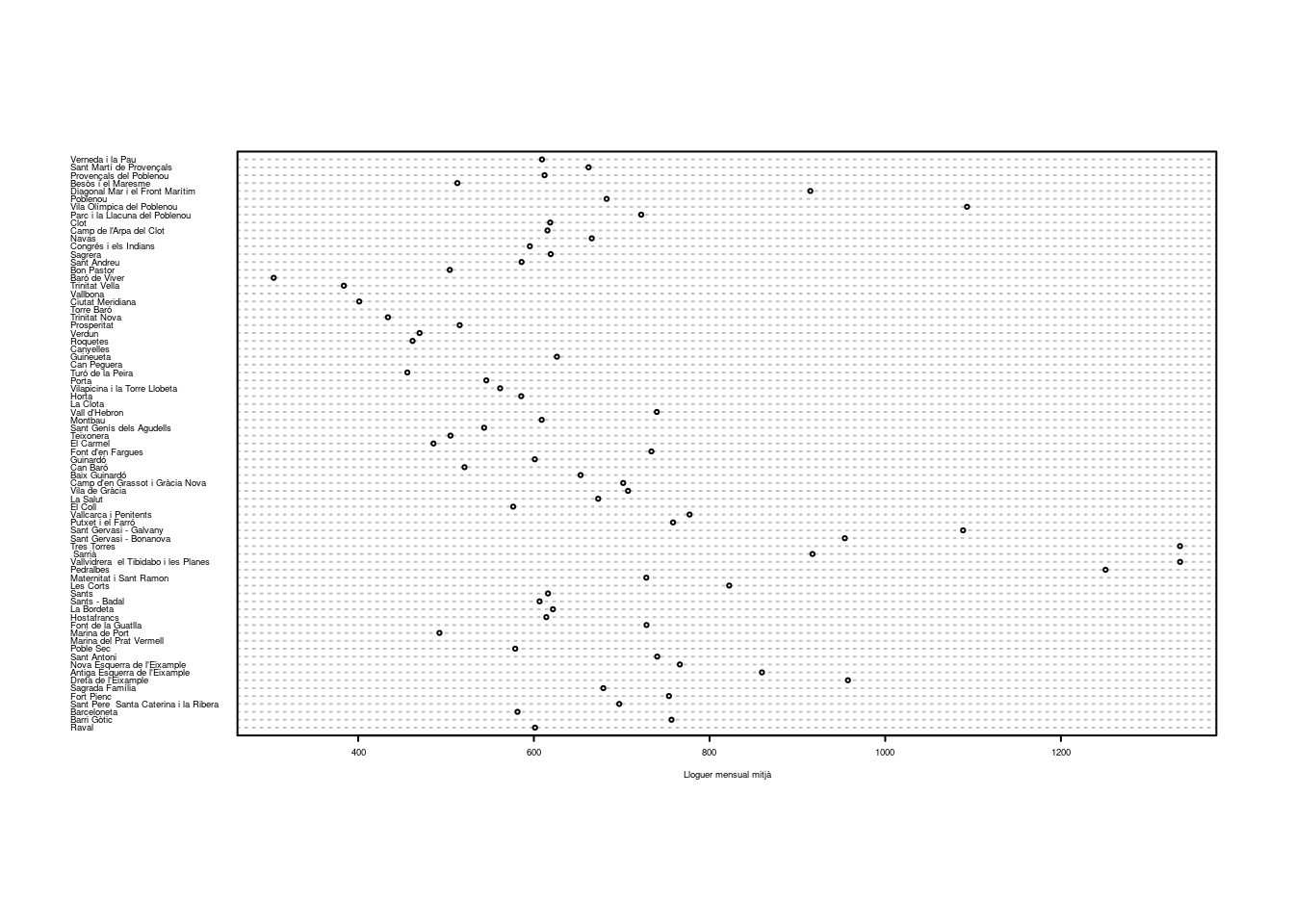
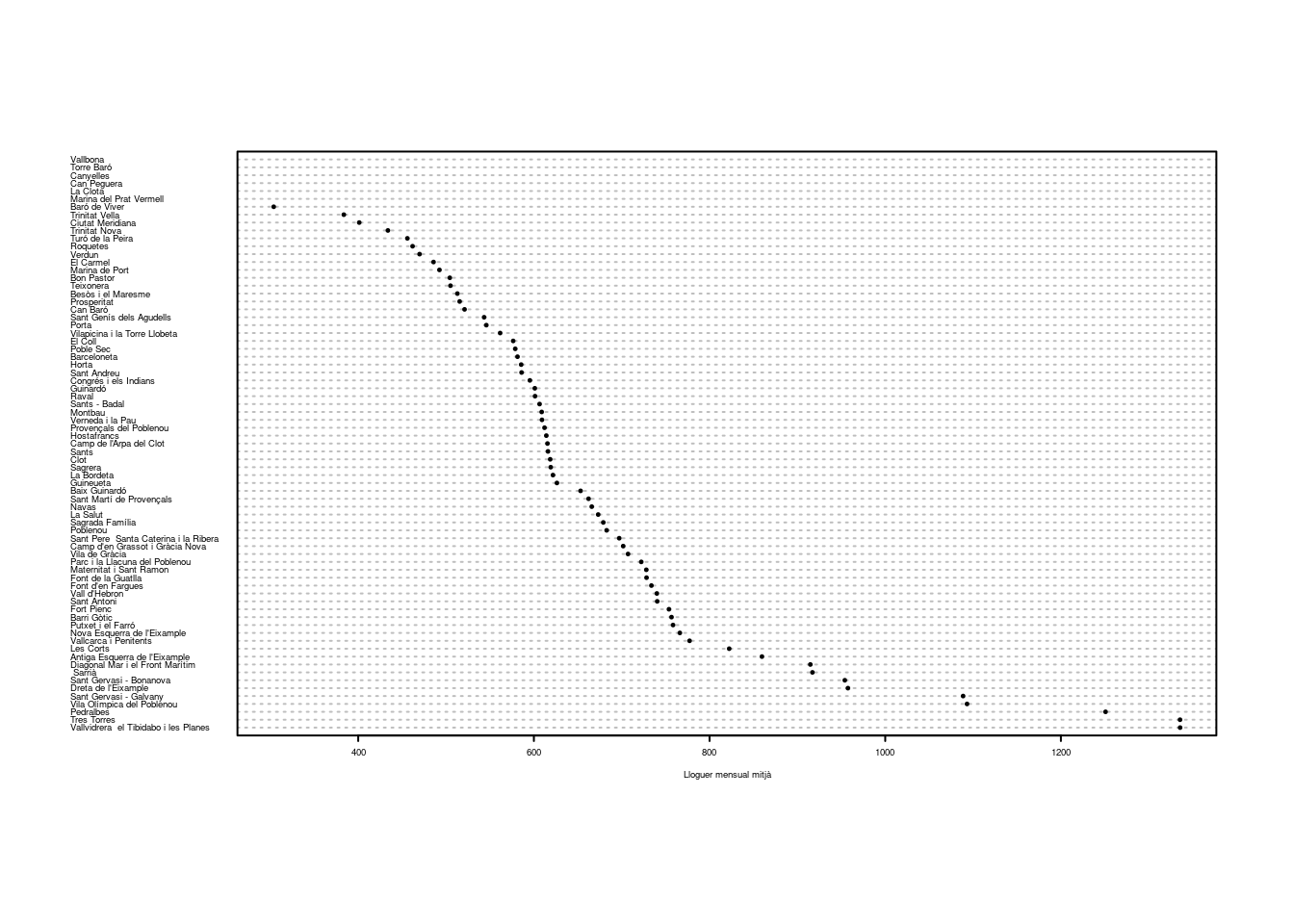
Un cop identificats els barris, la visualització es podria millorar encara afegint algun criteri d’ordenació dels barris. Aquesta decisió depèn de l’objectiu que tingui el nostre gràfic. Si, per exemple, volem mostrar fins a quin punt hi ha diferències entre els barris de tota la ciutat, hauríem d’ordenar els barris de major a menor lloguer mitjà, i aleshores seria senzill identificar els barris amb lloguers alts i baixos. Per fer-ho, crearem primer un objecte barris.ord que és un duplicat de la base de dades però ordenat per la variable T1 a través de la funció order(). Dins d’aquesta funció, l’argument decreasing = TRUE indica que volem que en el nou data frame la variable que hem ordenat comenci pels barris amb lloguer més alt i vagi baixant. Quan fem el gràfic de punts amb aquesta nova variable ordenada, la capacitat expressiva del gràfic augmenta de forma considerable. També hi ajuda que hem canviat la forma dels punts de cercles buits a sòlids de color negre (amb l’argument pch). Proveu a canviar el valor de pch per veure les possibilitats d’altres símbols per representar els punts.
barris.ord <- barris[order(barris$T1, decreasing = TRUE), ] # Creem un nou objecte
head(barris.ord) # Dades ordenades## districte barri T1 T2 T3 T4 T1_rec T1_dic T1_rec_3 T1_rec_3_en
## 22 5 Vallvidrera el Tibidabo i les Planes 1335.71 824.38 1119 841.10 Alt Alt Alt High
## 24 5 Tres Torres 1335.63 1337.79 1462 1385.99 Alt Alt Alt High
## 21 4 Pedralbes 1250.83 1711.45 2034 1860.30 Alt Alt Alt High
## 67 10 Vila Olímpica del Poblenou 1093.14 1116.30 1173 1015.10 Mig-Alt Alt Mig Medium
## 26 5 Sant Gervasi - Galvany 1088.66 1095.70 1262 1153.93 Mig-Alt Alt Mig Medium
## 7 2 Dreta de l'Eixample 957.55 988.89 1052 1035.07 Mig-Alt Alt Mig Medium
## T1_dic2 T1_quadrat T1_log
## 22 lloguer alt 36.54737 7.197218
## 24 lloguer alt 36.54627 7.197158
## 21 lloguer alt 35.36708 7.131563
## 67 lloguer alt 33.06267 6.996810
## 26 lloguer alt 32.99485 6.992703
## 7 lloguer alt 30.94430 6.864378dotchart(
barris.ord$T1,
labels = barris.ord$barri,
cex = 0.3,
xlab = "Lloguer mensual mitjà",
pch = 20
)
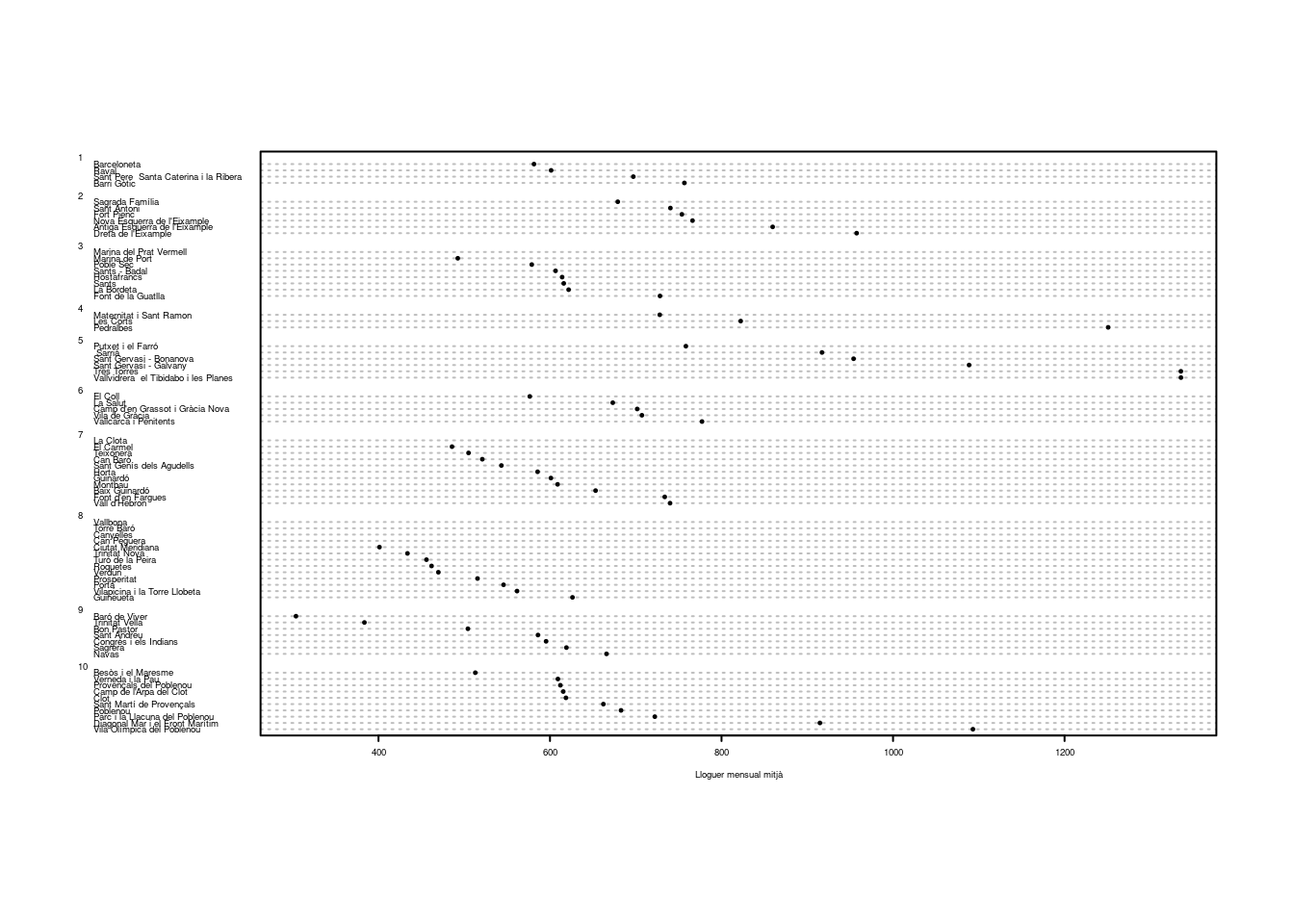
Si, en canvi, amb el nostre gràfic volguéssim representar la variació existent en el preu de lloguer entre els barris dins de cada districte, els barris haurien d’estar agrupats per districte. Ja que a la base de dades tenim una variable que ens especifica a quin districte pertany cada barri, aquesta possibilitat és senzilla de dur a terme amb l’argument groups. Per tal que puguem fer servir la variable districte com a valor d’argument, però, l’hem de convertir primer en un factor. Un cop fet, els barris ens queden agrupats per districtes i podem observar l’extrema variació entre barris en districtes com el 4 (Les Corts), el 5 (Sarrià-Sant Gervasi) i el 10 (Sant Martí), mentre que altres districtes com Gràcia (6), Horta-Guinardó (7) i Nou Barris (8) tenen barris una mica més homogenis en termes de lloguer mitjà.
barris.ord$districte <- factor(barris.ord$districte)
dotchart(
barris.ord$T1,
labels = barris.ord$barri,
cex = 0.3,
xlab = "Lloguer mensual mitjà",
pch = 20,
groups = barris.ord$districte
)
2.7.5 Exportació de gràfics
Amb RStudio hi ha bàsicament dues formes d’exportar els gràfics que creem. La primera és fent servir el menú de la finestra inferior dreta de la interfície de RStudio. En el menú Plots hi ha l’opció Export, que ens permetrà triar en quin format gràfic volem guardar el gràfic (pdf, png, jpeg, etc.), així com les mides del gràfic i el directori on el volem guardar. Com a recomanació general, és important guardar els gràfics en formats d’alta resolució, preferiblement basats en vectors com pdf, png, eps o svg. Una segona manera de guardar els gràfics és fer-ho directament en el codi. Per exemple, amb el següent codi guardaríem el darrer histograma al subdirectori del nostre projecte destinat a contenir els gràfics que creem:
pdf("graphs/histograma_blau.pdf", width=8, height=6)
hist(
barris$T1,
main = "Distribució del lloguer dels pisos dels barris de Barcelona",
xlab = "Lloguer mensual mitjà",
ylab = "Freqüència",
col = "blue",
breaks = 15,
xlim = c(200,1400),
ylim = c(0,14),
las = 1
)
dev.off()Segons el codi, primer hem creat un objecte gràfic en format pdf, on hem especificat la ruta i el nom del gràfic que volem guardar, així com la seva amplada i alçada. Després hi introduïm el codi del gràfic que volem crear. Finalment, amb dev.off() ordenem a R que tanqui l’objecte gràfic de pdf que havíem creat al principi, de manera que el gràfic en pdf queda creat i guardat a la carpeta que necessitem.
2.8 Descriptius estadístics
Un cop hem explorat les variables a través de gràfics, podem extreure els indicadors sintètics bàsics que ens completin la informació sobre la distribució de la variable. A banda de les funcions individuals per a cada indicador (e.g., mean(), sd()), hi ha moltes funcions a R que permeten obtenir diversos indicadors a la vegada. La funció més genèrica és summary(), que dóna 7 indicadors diferents. Si l’apliquem als preus mitjans de lloguer dels barris de Barcelona durant el primer trimestre:
summary(barris$T1)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 303.8 569.0 619.2 678.0 740.2 1335.7 6Per obtenir encara més informació, podem fer servir alguna de les funcions específiques de llibreries com Hmisc o psych, que contenen funcions molt útils per a les ciències socials. Per exemple, la funció describe() de la llibreria psych ens ofereix el nombre d’observacions, la mitjana, desviació estàndard, mediana i altres mesures de desviació i distribució:
library(psych)
describe(barris$T1)## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 67 678.04 205.32 619.16 653.21 153.7 303.8 1335.71 1031.91 1.35 2.13 25.08De vegades, finalment, volem obtenir aquests indicadors d’una variable, però condicionat als valors d’alguna altra variable. Per fer-ho també hi ha opcions diverses. Si voleu continuar amb una funció de la llibreria psych, podem obtenir la mitjana del lloguer dels barris condicionat per districtes ho podem obtenir mitjançant la funció describeBy(), en què hem d’identificar el grup, és a dir, la variable categòrica per la qual volem condicionar. Obtenim així tots els indicadors per a cada districte:
describeBy(barris$T1, group = barris$districte)##
## Descriptive statistics by group
## group: 1
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 4 659.12 82.37 649.23 659.12 85.86 581.34 756.68 175.34 0.14 -2.24 41.19
## ----------------------------------------------------------------------------------------------
## group: 2
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 6 792.76 99.53 759.97 792.76 74.5 679.03 957.55 278.52 0.52 -1.41 40.63
## ----------------------------------------------------------------------------------------------
## group: 3
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 7 608.27 69.46 614.15 608.27 11.37 492.49 728.25 235.76 0.07 -0.62 26.25
## ----------------------------------------------------------------------------------------------
## group: 4
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 3 933.73 278.64 822.36 933.73 139.91 727.99 1250.83 522.84 0.34 -2.33 160.88
## ----------------------------------------------------------------------------------------------
## group: 5
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 6 1064.93 234.63 1021.33 1064.93 272.12 758.44 1335.71 577.27 0.08 -1.89 95.79
## ----------------------------------------------------------------------------------------------
## group: 6
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 5 687.15 72.77 701.69 687.15 42.24 576.44 777.25 200.81 -0.32 -1.46 32.54
## ----------------------------------------------------------------------------------------------
## group: 7
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 10 597.76 89.5 593.3 593.98 97.93 485.74 740 254.26 0.38 -1.38 28.3
## ----------------------------------------------------------------------------------------------
## group: 8
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 9 496.87 71.09 469.83 496.87 67.7 401.17 626.23 225.06 0.4 -1.23 23.7
## ----------------------------------------------------------------------------------------------
## group: 9
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 7 522.59 133.36 585.98 522.59 118.47 303.8 665.89 362.09 -0.52 -1.55 50.4
## ----------------------------------------------------------------------------------------------
## group: 10
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 10 704.35 172.39 640.41 679.68 54.57 512.89 1093.14 580.25 1.13 -0.01 54.51Si no necessitem tots els indicadors sinó que fem amb un de sol (per exemple, la mitjana), podem fer servir la funció genèrica (que tenim instal·lada per defecte amb R) aggregate():
aggregate(T1 ~ districte, mean, data=barris)## districte T1
## 1 1 659.1225
## 2 2 792.7617
## 3 3 608.2700
## 4 4 933.7267
## 5 5 1064.9283
## 6 6 687.1500
## 7 7 597.7590
## 8 8 496.8689
## 9 9 522.5929
## 10 10 704.3460Obtindreu més informació sobre l’obtenció d’estadístics descriptius de variables aquí.
2.9 Taules de contingència
Al darrer exercici us demanava que transforméssiu una taula de freqüències en una taula de contingència. Les taules de contingència són el resultat de creuar dues variables categòriques i s’expressen en percentatges. Aquests percentatges, però, poden ser de tipus diferents i, de fet, poden expressar informacions molt diferents. Vegem-ho.
Treballarem amb una mostra del tractament rebut pels detinguts per possessió de marihuana a una ciutat del Canadà, que es troben en una base de dades (arrests.csv) que teniu al Campus Virtual:
arrests <- read.csv("data/arrests.csv", sep = ",")
head(arrests)## released colour year age sex employed citizen checks id
## 1 Yes White 2002 21 Male Yes Yes 3 1
## 2 No Black 1999 17 Male Yes Yes 3 2
## 3 Yes White 2000 24 Male Yes Yes 3 3
## 4 No Black 2000 46 Male Yes Yes 1 4
## 5 Yes Black 1999 27 Female Yes Yes 1 5
## 6 Yes Black 1998 16 Female Yes Yes 0 6Aquesta base de dades va molt bé per practicar perquè inclou tant variables categòriques (dicotòmiques i nominals) com contínues. Les variables que conté estan detallades a la Taula \(\ref{tab:arrests}\).
| Variable | Descripció |
|---|---|
released |
Si l’individu fou deixat anar després de ser detingut (Yes) o no. |
colour |
Raça de l’individu detingut (Black / White) |
age |
Edat de l’individu detingut (en anys) |
sex |
Sexe de l’individu detingut (Male / Female) |
employed |
Si l’individu detingut treballa (Yes) o estŕ aturat (No) |
citizen |
Si l’individu detingut és ciutadà nord-americà (Yes) o no. |
checks |
Nombre de bases de dades policials que la policia consulta abans de |
| decidir si el deixa anar. | |
id |
Identificador únic per a cada individu detingut. |
2.9.1 Taules de doble entrada
Una preocupació constant en el comportament policial (no només als Estats Units) és si els ciutadans tenen la mateixa probabilitat de ser detinguts o, un cop detinguts, deixats en llibertat, o bé hi ha ciutadans que, per raó de raça, gčnere o edat tenen més probabilitats de ser detinguts i empresonats. Per explorar aquesta qüestió amb les dades que tenim, creuarem les variables colour (raça del detingut) i released (posat en llibertat o retingut). Començarem fent una taula simple de freqüčncies, que podem obtenir de diverses maneres, tot i que ens centrarem en dues, de moment:
t <- table(arrests$released, arrests$colour) # amb la funció table()
t <- xtabs(~released + colour, data=arrests) # amb la funció xtabs()
t## colour
## released Black White
## No 333 559
## Yes 955 3379Fixem-nos que les dues funcions que hem fet servir (table() i xtabs()) utilitzen una sintaxi una mica diferent per obtenir el mateix resultat. La funció table() és literal i els seus arguments corresponen, primer, a la variable que constituirà les files i, segon, a la que volem en les columnes. En canvi, xtabs() comença amb el símbol de la fórmula (~), després els noms de les variables que volem creuar (separades per un signe \(+\)), i finalment el nom del data frame del qual s’han d’extreure les variables. Tot i que pot semblar que xtabs() és més complicat que table(), la seva sintaxi és més neta, perquè separa els tipus d’arguments (variables per una banda, nom del data frame per un altre). Però hi ha un segon argument que la fa superior a table() i és que permet utilitzar variables de ponderació a l’hora de fer taules. En cas que tinguéssim una variable de ponderació, posaríem el seu nom abans del signe ~ i aleshores les freqüències ens apareixerien ponderades.
Tanmateix, només amb nombres absoluts no fem massa coses. Si necessitem fer una taula amb percentatges, farem servir la funció prop.table() sobre la taula que ja hem creat:
prop.table(t)## colour
## released Black White
## No 0.06371986 0.10696517
## Yes 0.18274015 0.64657482Veiem que si l’apliquem sense més, R ens calcula les proporcions de cada cel·la respecte del total. Però pot ser que vulguem obtenir (1) percentatges en comptes de proporcions i (2) que aquests percentatges siguin per fila o per columna. Si volem percentatges, l’únic que hem de fer és multiplicar la taula per 100. Si els volem fer per columna, haurem d’especificar la direcció dels percentatges amb un 2 (1 seria per fila):
prop.table(t) * 100## colour
## released Black White
## No 6.371986 10.696517
## Yes 18.274015 64.657482Aquesta taula ens indica que el 64.6% dels detinguts per la policia són blancs i foren deixats anar. Si volem saber el percentatge dels blancs que foren deixats anar, però, necessitem crear percentatges-columna:
prop.table(t, 2) * 100## colour
## released Black White
## No 25.85404 14.19502
## Yes 74.14596 85.80498Així, ara veiem que un 85.8% dels blancs detinguts foren deixats anar, mentre que en el cas dels negres aquest percentatge és del 74.1%. Tanmateix, amb aquesta taula no podem saber quants blancs i negres hi ha entre aquells als quals la policia ha deixat anar. Si ho volem saber hem de crear percentatges-fila:
prop.table(t, 1) * 100## colour
## released Black White
## No 37.33184 62.66816
## Yes 22.03507 77.96493Amb aquesta taula, sabem que un 78% dels individus que foren deixats anar després de ser detinguts eren blancs, mentre que un 22% eren negres.
També podem obtenir taules que ens donin tota la informació necessària d’una sola vegada. Per exemple, dins de la llibreria gmodels hi ha una funció (CrossTable()) que permet construir taules amb tots els percentatges a la vegada, així com informació sobre algun indicador d’associació entre les variables. Podeu trobar informació sobre la resta d’arguments d’aquesta funció aquí. Per obtenir una taula amb un format semblant al de SPSS:
library(gmodels)
CrossTable(arrests$released, arrests$colour, format="SPSS")##
## Cell Contents
## |-------------------------|
## | Count |
## | Chi-square contribution |
## | Row Percent |
## | Column Percent |
## | Total Percent |
## |-------------------------|
##
## Total Observations in Table: 5226
##
## | arrests$colour
## arrests$released | Black | White | Row Total |
## -----------------|-----------|-----------|-----------|
## No | 333 | 559 | 892 |
## | 58.245 | 19.050 | |
## | 37.332% | 62.668% | 17.069% |
## | 25.854% | 14.195% | |
## | 6.372% | 10.697% | |
## -----------------|-----------|-----------|-----------|
## Yes | 955 | 3379 | 4334 |
## | 11.988 | 3.921 | |
## | 22.035% | 77.965% | 82.931% |
## | 74.146% | 85.805% | |
## | 18.274% | 64.657% | |
## -----------------|-----------|-----------|-----------|
## Column Total | 1288 | 3938 | 5226 |
## | 24.646% | 75.354% | |
## -----------------|-----------|-----------|-----------|
##
## Les dades semblen indicar que, en efecte, hi ha diferčncies entre negres i blancs a l’hora de ser posats en llibertat per la policia després de ser detinguts. En concret, mentre un 74% dels negres detinguts són posats en llibertat, entre els blancs ho són gairebé el 86%.
De tota manera, tot i tenir el valor de la \(\chi^2\), la taula no ens diu quin és el resultat d’aplicar un test de \(\chi^2\) d’associació entre les dues variables que hi ha a la taula. Això ho veurem a la sessió sobre anŕlisi bivariada.
Finalment, podem representar el contingut d’una taula de contingència de manera gràfica. En concret, els gràfics de mosaic ens permeten representar la grandària relativa de cada creuament d’una taula:
s <- prop.table(t, 2) * 100
mosaicplot(s)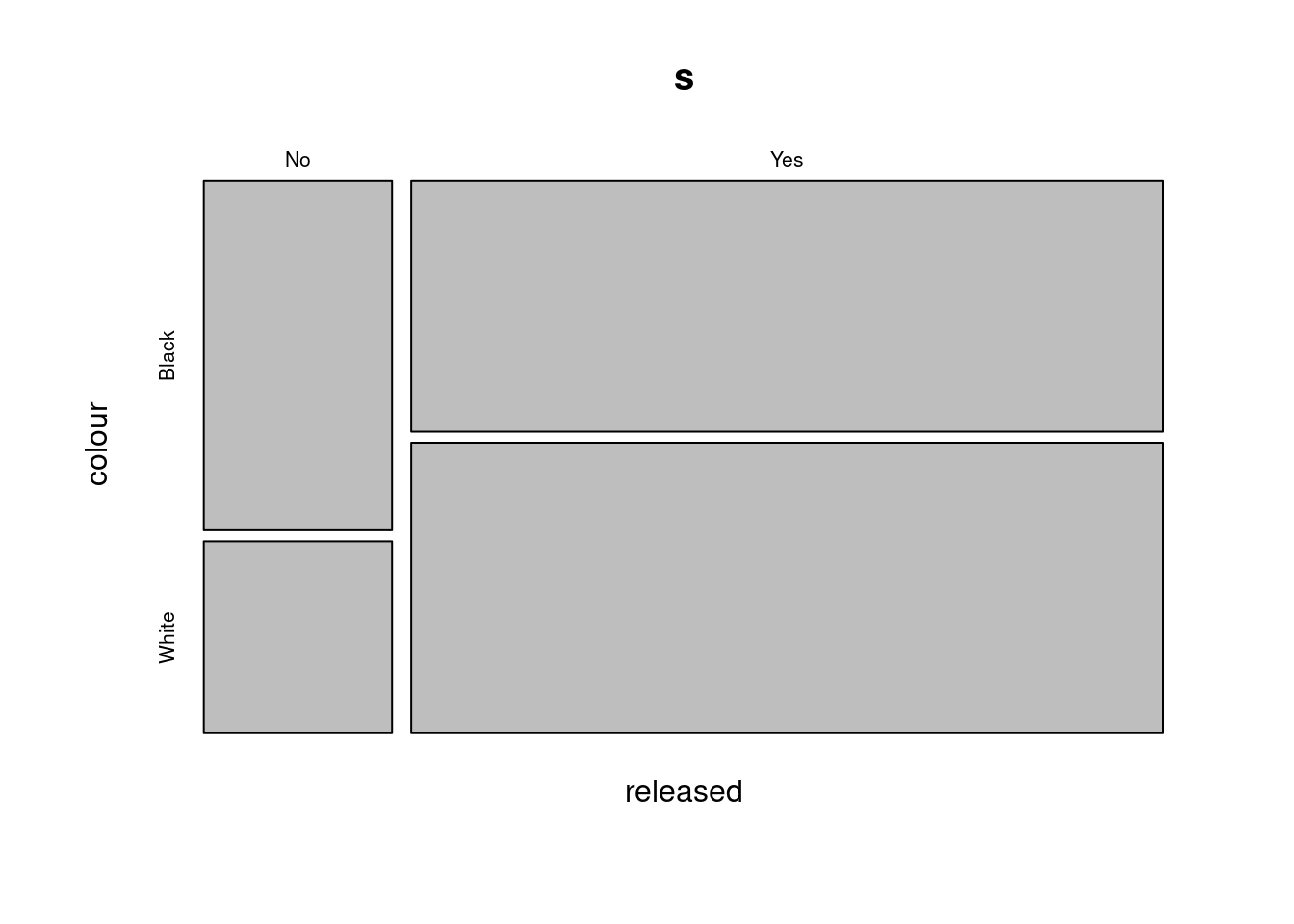
2.9.2 Taules més complexes
Les taules de contingència no només han de ser de doble entrada (dues variables), sinó que en poden tenir més. Ara bé, hem de ser conscients que més de tres variables representades en una taula impliquen ja un esforç excessiu per a un lector a l’hora d’interpretar-ne els resultats. Veurem un exemple de tres variables. Per continuar amb l’exemple anterior, podem voler esbrinar si la relació entre colour i released estŕ en realitat afectada per la situació laboral dels detinguts. La variable employed precisament mesura si els individus treballen (Yes) o estan aturats (No).
Per fer aquesta taula amb tres dimensions, només cal afegir la tercera variable a la funció que fem servir per crear la taula de doble entrada:
t2 <- table(arrests$released, arrests$colour, arrests$employed)
t2 <- xtabs(~ released + colour + employed, data = arrests)
t2## , , employed = No
##
## colour
## released Black White
## No 148 201
## Yes 229 537
##
## , , employed = Yes
##
## colour
## released Black White
## No 185 358
## Yes 726 2842Observem que la representació de la taula ja és complexa. Hem creat una taula que ens mostra els resultats separats per la tercera variable (employed). Si volem obtenir percentatges-columna:
prop.table(t2, 2) * 100## , , employed = No
##
## colour
## released Black White
## No 11.490683 5.104114
## Yes 17.779503 13.636364
##
## , , employed = Yes
##
## colour
## released Black White
## No 14.363354 9.090909
## Yes 56.366460 72.168614Però fixem-nos que aquest comandament ens crea percentatges-columna que cobreixen tota la columna, és a dir, que inclouen els que treballen i els que no. Així, sabem que un 11.49% dels detinguts negres no els van deixar anar després de ser detinguts i eren aturats. Però això no ens diu quin percentatge dels negres que estaven aturats no van deixar després de ser detinguts. Per obtenir percentatges-columna dins de la tercera variable, hem d’especificar els marges de la taula. En l’exemple, ho fem amb l’argument margin, on hem de dir primer la variable dins de la qual volem que es calculin els percentatges, i després en quina direcció volem els percentatges. Com que els volem per columna hi posarem un \(2\):
prop.table(t2, margin = c(3, 2)) * 100## , , employed = No
##
## colour
## released Black White
## No 39.25729 27.23577
## Yes 60.74271 72.76423
##
## , , employed = Yes
##
## colour
## released Black White
## No 20.30735 11.18750
## Yes 79.69265 88.81250Ara sí, sabem que entre els negres aturats, el 60.7% foren deixats anar després de ser detinguts, mentre que entre els negres amb ocupació aquest percentatge és gairebé del 80%. Entre els blancs aquesta relació també es manté, cosa que indica que la situació laboral—a banda de la raça—podria ser un factor important a l’hora d’explicar la probabilitat de ser deixat anar després de ser detingut.
2.9.3 Taules planes
Una forma alternativa d’especificar taules complexes és fer-les planes amb la funció ftable(). Un cop hem creat la taula de tres entrades, aquesta funció ens la presenta en dues dimensions, perň li hem d’especificar quines variables volem que es representin en columnes:
ftable(t2, col.vars=c("colour", "employed"))## colour Black White
## employed No Yes No Yes
## released
## No 148 185 201 358
## Yes 229 726 537 2842En cas que vulguem percentatges-columna per alguna de les dues variables que es troben a les columnes, tal i com hem fet abans, li haurem d’especificar els marges exactes. En aquest cas, volem que dins de cada categoria de color de pell, calculi els percentatges-columna:
ftable(
100 * prop.table(t2, margin = c(3, 2)),
col.vars=c("colour", "employed")
)## colour Black White
## employed No Yes No Yes
## released
## No 39.25729 20.30735 27.23577 11.18750
## Yes 60.74271 79.69265 72.76423 88.81250Si hi ha massa decimals, els reduďm amb la funció round(), que podem aplicar sobre qualsevol objecte de R i en la qual el principal argument és el nombre de digits que volem obtenir en els decimals. En aquest cas li diem que volem només dos decimals:
tf2 <- ftable(
100 * prop.table(t2, margin = c(3, 2)),
col.vars=c("colour", "employed")
)
round(tf2, digits = 2)## colour Black White
## employed No Yes No Yes
## released
## No 39.26 20.31 27.24 11.19
## Yes 60.74 79.69 72.76 88.81Per a més funcions amb taules de contingència, feu un cop d’ull a la llibreria memisc creada pel politòleg Martin Elff.
2.10 Exercicis: Conceptes bàsics
2.10.1 Codificació de variables
Baixa les dades
barris_poblacio.csvque hi ha al Campus Virtual i guarda’ls en el subdirectori/datadel teu projecte de la sessió d’avui.Carrega les dades a R, especificant la codificació “UTF-8” per a les dades amb caràcters especials (com els accents). Les dades mostren informació demogràfica dels barris de Barcelona: la seva població total i la seva població estranjera.
Crea una nova variable
por.extque representi, per cada barri, el percentatge de població estrangera sobre el total de població.Crea una nova variable dicotòmica
ext.dicde manera que la categoriaaltagrupi els barris amb un percentatge d’estrangers superior a la mitjana, ibaixla resta de barris.Crea una nova variable categòrica
ext.quarta partir de la variable de percentatge de població estrangera, de manera que els seus 4 nivells coincideixin amb els quartils 1, 2, 3 i 4. Fes que les categories tinguin les etiquetes “Baja”, “Mitjana-Baixa”, “Mitjana-Alta” i “Alta”. Pensa en com fer-ho. Explora les funcionssummary()iquantile().Crea un boxplot que mostri la distribució de la variable
por.ext. Comenta breument el resultat. Per exemple, quin és el percentatge medià d’estrangers?Crea un boxplot que mostri la distribució de població estrangera de cada grup de la variable
ext.quart.Crea un gràfic de punts on mostris la distribució del percentatge de població estrangera per barris de Barcelona. Força l’eix horitzontal (x) a reprsentar valors entre 0 i 60. Decideix quin criteri d’ordenació vols mostrar i executa’l.
2.10.2 Importació SPSS
L’objectiu de la segona part de l’exercici és continuar practicant amb la càrrega de dades i la creació i recodificació de variables. Per fer-ho, utilitzarem dades de l’estadística oficial. Concretament, l’Encuesta sobre la participación de la población adulta en las actividades de aprendizaje (EADA) de l’any 2011, que trobaràs al Campus Virtual. (Més detalls sobre aquestes dades aquí).
Carrega la base de dades
EADA.sav(pista: és un format de SPSS).Recodifica la variable
MAINSTATque mesura la situació laboral dels individus. Agrupa els diferents valors de la variable en 3 categories: ocupats, desocupats i inactius. Els que han respost “Otra situación” o “Negativa/No sabe”, declara’ls valors perduts.Recodifica la variable que mesura el nivell d’estudis
HATLEVEL1. Fes-ho de forma que quedin 3 categories: una que agrupi els que no tenen cap títol acadèmic formal i els que tenen el “Nivel básico”, mantenint les altres dues (“Nivel superior” i “Nivel medio”).Crea una taula de contingència que relacioni el nivell d’estudis dels entrevistats amb la seva situació laboral. Explora la funció
prop.table()(pensa que l’argument d’aquesta funció ha de ser una taula).Ara has de crear una vairable
EDATa partir de la variableBIRTHYEAR. Per fer-ho has de calcular l’edat dels entrevistats. Tingues en compte que l’enquesta es va realitzar el 2011. Mostra la distribució de la variableEDATmitjançant un histograma. Cuida d’arreglar els títols dels eixos per tal que quedi presentable. Treu el títol general del gràfic que ve per defecte. Augmenta els límits de l’eix vertical de manera que cobreixi valors entre el 0 i el 2500. Fes que les barres siguin de color gris.Crea una variable categòrica (en llenguatge R, un
factor) d’edat amb 3 trams d’edat: \(18-35\), \(36-50\), \(51-65\). ¿Quants individus es troben en cada interval d’edat? Mostra-ho en un gràfic de barres i assegura’t que en els noms de les barres els intervals apareguin entre dos claudàtors (és a dir, “[18-35]”).
2.10.3 Importació CIS
Baixa les dades
cis3187.savque hi ha al Campus Virtual i guarda’ls al subdirectori/datadel teu projecte de la sessió d’avui.Carrega les dades a R. Les dades corresponen al Baròmetre de setembre de 2017 del Centro de Investigaciones Sociológicas. Tingues en compte que estan en format
.sav.Mira les categories de la pregunta P31 del qüestionari. Es tracta d’una preguna sobre el record de participació a les eleccions legislatives espanyoles de 2016. Crea una variable nova
P31Rde manera que sigui un factor amb només 2 categories: (1) aquells que van votar; (0) aquells que no van votar. ¿Quants entrevistats hi ha de cada tipus?La variable
ESTUDIOSmesura el nivell educatiu dels entrevistats. Neteja la variableESTUDIOSde no respostes i fes una taula de contingència amb percentatges en la qual la variableP31Rsigui la dependent (columnes) i el nivell d’estudis la variable independent (files).La variable
P33mesura l’edat an anys dels entrevistats. Crea una variable nova amb tres categories d’edat:
- “Jove”: aquells que tenen l’edat corresponent al primer quartil
- “Mitjana”: aquells que tenen l’edat entre el primer quartil i el tercer quartil
- “Gran”: aquells que són majors de l’edat que marca el tercer quartil
Afegeix aquesta nova variable a la taula de contingència que havies creat per veure si l’efecte del nivell educatiu sobre la participació electoral és igual en els tres nivells d’edat.
Selecciona una sub-mostra de les dades que correspongui només als entrevistats catalans de la mostra. Mira si la relació entre estudis, edat i participació és diferent a Catalunya que en l’agregat d’Espanya. ¿Quins problemes observes?
2.10.4 Importació CEO
Baixa les dades
ceo-863.csvque hi ha en el Campus Virtual y guarda’ls en el subdirectori/datadel teu projecte de la sessió d’avui.Carrega les dades a R. Les dades corresponen al Baròmetre d’Opinió Política. 3a onada 2017 - REO 863 del Centre d’Estudis d’Opinió, que inclou preferències polítiques dels ciutadans. Tingues en compte que les columnes estan separades per punt i coma (“;”) i que els decimals són comes (“,”).
Crea un nou
data frameanomenatceo2que només contingui les següents variables:P4,P30,PONDERA,C500iC100.Mira les categories de la pregunta
P4del qüestionari. Es tracta d’una pregunta sobre la percepció dels enquestats sobre la situació econòmica de Catalunya. Transforma la variableP4de manera que sigui un factor anomenatP4R. Si vols, fes que les teves categories corresponguin amb les de la pregunta del qüestionari (“Molt bona”, “Bona”, etc.). Decideix què fer amb els valors98.La variable P30 mesura les preferències de l’estatus polític de Catalalunya, amb quatre opcions. Transforma la variable en un factor (
P30R) i fes que les etiquetes de les categories apareguin en la variable.Crea una taula de contingència que creuï la percepció de la situació econòmica i les preferències territorials dels enquestats. La variable dependent aquí és la preferència territorial. ¿Existeix relació entre les preferències territorials i la percepció de la situació econòmica? Si hi és, ¿en quin sentit?
Crea ara la mateixa taula de contingència però ponderant les dades amb la variable
PONDERA. ¿Fins a quin punt canvien els resultats?Crea ara una variable dicotòmica a partir de la variable de nivell educatiu
C500, amb els únics valors següents:Baix: individus amb un nivell educatiu inferior a Batxillerat, BUP, COU, etc. (nivell 5 de la variable)Alt: la resta d’individus
Afegeix aquesta tercera variable a la taula de contingència de la pregunta anterior i compara si la relació entre preferència territorial i percepció de la situació econòmica es manté igual en individus de nivell educatiu
BaixiAlt.Fes una taula de contingència que relacioni la percepció sobre la situació econòmica de Catalunya (
P4R) amb les preferències territorials (P30R), però només per aquells individus que hagin nascut a Catalunya (preguntaC100). ¿Quants són? ¿Els resultats són gaire diferents que per la població general?