Capítol 4 Transformació de l’estructura de les dades
4.1 Introducció
Recordem els tres principis bàsiques de les dades endreçades:
- Cada variable ha de tenir la seva columna
- Cada observació ha de tenir la seva fila
- Cada valor ha de tenir la seva cel·la
Les dades que ens arriben per a l’anàlisi rarament compleixen aquests principis. Sovint no en compleixen cap i la nostra feina implica canviar-ne l’estructura per tal que puguem treballar amb dades endreçades, que sempre ens farà la vida molt més fàcil. Eines com ggplot2 i dplyr estan dissenyades perquè cada variable tingui la seva columna.
Les 4 funcions bàsiques per canviar l’estructura de les dades amb tidyverse són:
- Transformar dades en què una variable està repartida en diverses columnes (dades amples) en dades on cada variable té una columna (dades llargues), amb la funció
pivot_longer() - Transformar dades en què cada observació en comptes d’estar en una sola fila ho està en més d’una fila (amb la funció
pivot_wider()) - Separar una columna en dues perquè en realitat representa dues variables diferents (amb la funció
separate()) - Unir dues columnes en una de sola perquè en realitat és la unió de les dues columnes el que representa una sola variable (amb la funció
unite())
4.2 pivot_longer() per fer llargues dades que són amples
Sovint les dades ens vénen de tal manera que una mateixa variable està repartida per diverses columnes, com en les dades sobre renda familiar de Barcelona:
rfd <- read_csv("data/rfd_bcn.csv")## Rows: 73 Columns: 5
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): BARRIS
## dbl (4): DTE, 2008, 2009, 2010
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.rfd## # A tibble: 73 × 5
## DTE BARRIS `2008` `2009` `2010`
## <dbl> <chr> <dbl> <dbl> <dbl>
## 1 1 1. el Raval 626 620 620
## 2 1 2. el Barri Gòtic 808 943 923
## 3 1 3. la Barceloneta 659 644 726
## 4 1 4. Sant Pere Santa Caterina i la Ribera 818 888 912
## 5 2 5. el Fort Pienc 1083 1091 1085
## 6 2 6. la Sagrada Família 1007 984 973
## 7 2 7. la Dreta de l'Eixample 1380 1436 1441
## 8 2 8. l'Antiga Esquerra de l'Eixample 1228 1226 1259
## 9 2 9. la Nova Esquerra de l'Eixample 1166 1143 1152
## 10 2 10. Sant Antoni 1029 995 954
## # … with 63 more rowsAquesta base de dades mostra l’índex de Renda Familiar Disponible (en base 10000) dels barris de Barcelona durant tres anys diferents. La base de dades expressa 4 variables: districte, barri, RFD i any, però en canvi hi ha 5 columnes. Si les dades han de seguir els principis de tidy data, aleshores hi ha d’haver 4 columnes: districte, barri, any i RFD. Per fer-ho, farem servir la funció pivot_longer():
rfd_g <- rfd %>%
pivot_longer(cols = -c(DTE, BARRIS), names_to = "ANYS", values_to = "RENDA")
rfd_g## # A tibble: 219 × 4
## DTE BARRIS ANYS RENDA
## <dbl> <chr> <chr> <dbl>
## 1 1 1. el Raval 2008 626
## 2 1 1. el Raval 2009 620
## 3 1 1. el Raval 2010 620
## 4 1 2. el Barri Gòtic 2008 808
## 5 1 2. el Barri Gòtic 2009 943
## 6 1 2. el Barri Gòtic 2010 923
## 7 1 3. la Barceloneta 2008 659
## 8 1 3. la Barceloneta 2009 644
## 9 1 3. la Barceloneta 2010 726
## 10 1 4. Sant Pere Santa Caterina i la Ribera 2008 818
## # … with 209 more rowsEls arguments necessaris d’aquesta funció són cols, names_to i values_to. L’argument cols identifica les columnes afectades per la transformació; en aquest cas són les tres columnes que identifiquen els tres anys, però també podem fer-ho de forma negativa, és a dir, totes les columnes excepte DTE i BARRIS. L’argument names_to ens demana quin nom volem que tingui la nova variable que contindrà els valors que actualment són els noms de les columnes afectades per la transformació; en el nostre cas, això són els anys (ANYS). L’argument values_to ens demana quin nom tindrà la variable que contindrà els valors que ara mateix estan sota cadascuna de les columnes afectades (RENDA).
L’operació que hem fet es pot observar a la Figura \(\ref{fig:gather}\): els noms de les columnes que representen els anys han passat a ser valors de la columna ANY, mentre que els valors de les cel·les que estaven repartits per diverses columnes ara pertanyen a la columna RFD.
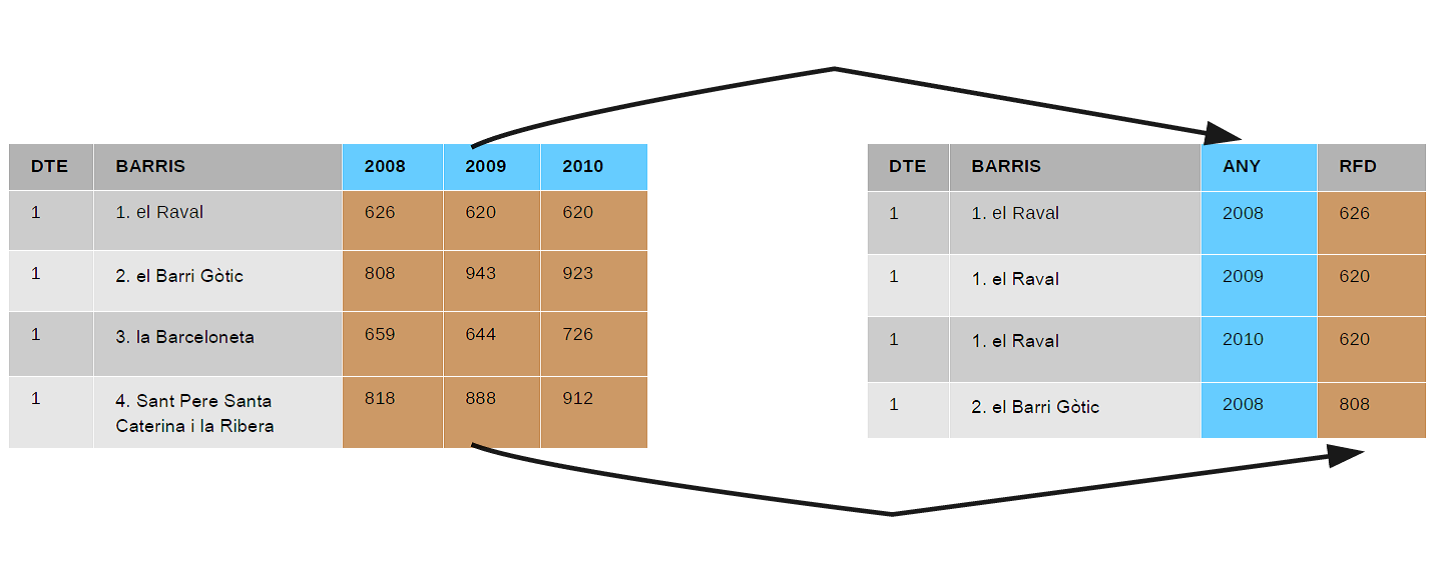
Conversió de dades amples a dades llargues.
Ara ja podem fer un gràfic per representar l’evolució en renda familiar disponible, per exemple, dels barris del districte de l’Eixample entre 2008 i 2010:
## # A tibble: 18 × 4
## DTE BARRIS ANYS RENDA
## <dbl> <chr> <chr> <dbl>
## 1 2 5. el Fort Pienc 2008 1083
## 2 2 5. el Fort Pienc 2009 1091
## 3 2 5. el Fort Pienc 2010 1085
## 4 2 6. la Sagrada Família 2008 1007
## 5 2 6. la Sagrada Família 2009 984
## 6 2 6. la Sagrada Família 2010 973
## 7 2 7. la Dreta de l'Eixample 2008 1380
## 8 2 7. la Dreta de l'Eixample 2009 1436
## 9 2 7. la Dreta de l'Eixample 2010 1441
## 10 2 8. l'Antiga Esquerra de l'Eixample 2008 1228
## 11 2 8. l'Antiga Esquerra de l'Eixample 2009 1226
## 12 2 8. l'Antiga Esquerra de l'Eixample 2010 1259
## 13 2 9. la Nova Esquerra de l'Eixample 2008 1166
## 14 2 9. la Nova Esquerra de l'Eixample 2009 1143
## 15 2 9. la Nova Esquerra de l'Eixample 2010 1152
## 16 2 10. Sant Antoni 2008 1029
## 17 2 10. Sant Antoni 2009 995
## 18 2 10. Sant Antoni 2010 954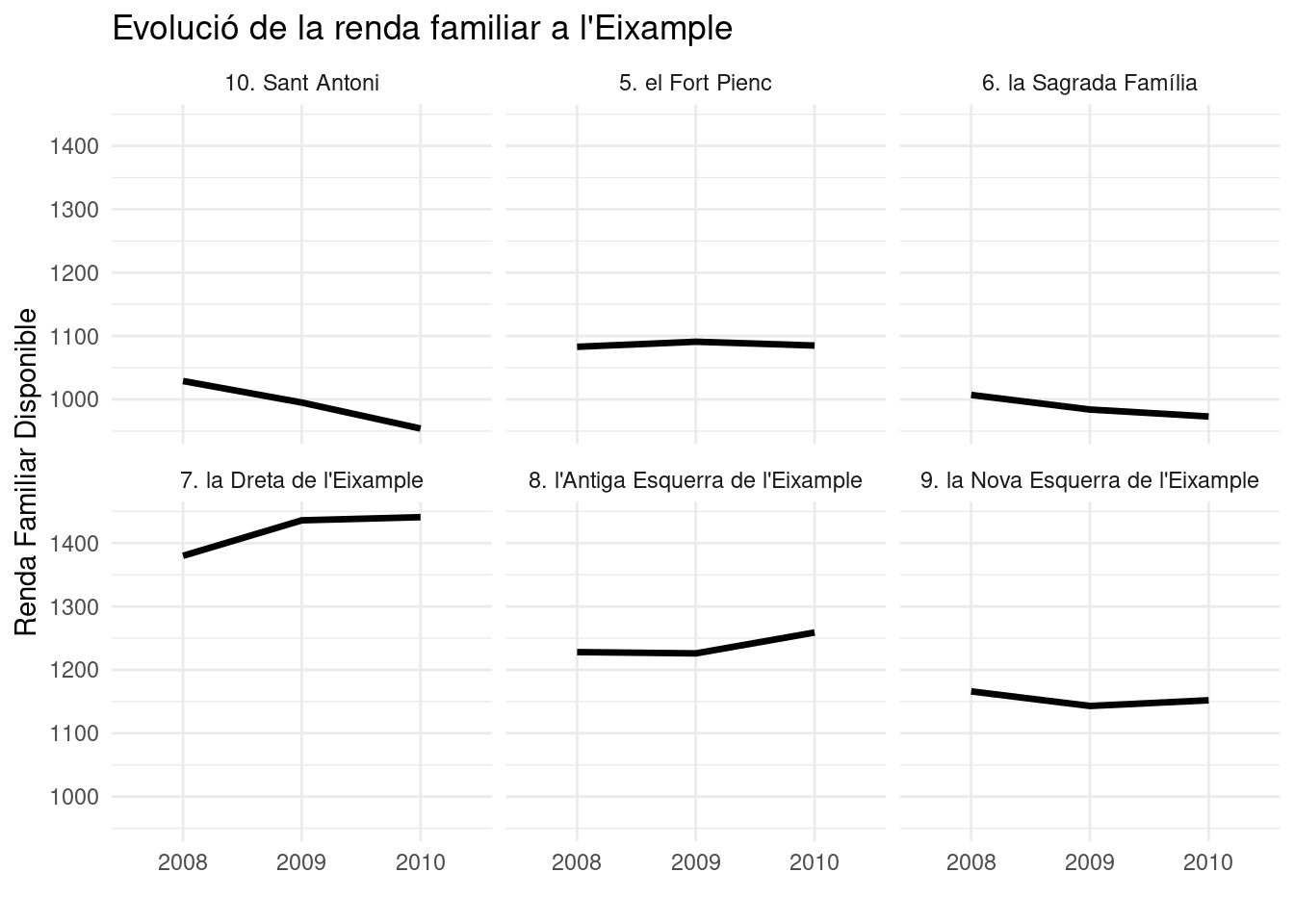
4.3 pivot_wider() per convertir dades llargues en dades amples
Mireu les següents dades sobre barris de Barcelona:
barris <- read_csv("data/rendafam2010_ample.csv")## Rows: 146 Columns: 4
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): BARRIS, MESURA
## dbl (2): DTE, VALOR
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.barris## # A tibble: 146 × 4
## DTE BARRIS MESURA VALOR
## <dbl> <chr> <chr> <dbl>
## 1 2 10 Sant Antoni POBLACIO 38414
## 2 2 10 Sant Antoni RFD 954
## 3 3 11 el Poble Sec POBLACIO 41138
## 4 3 11 el Poble Sec RFD 666
## 5 3 12 la Marina del Prat Vermell POBLACIO 1069
## 6 3 12 la Marina del Prat Vermell RFD 619
## 7 3 13 la Marina de Port POBLACIO 30134
## 8 3 13 la Marina de Port RFD 744
## 9 3 14 la Font de la Guatlla POBLACIO 1031
## 10 3 14 la Font de la Guatlla RFD 824
## # … with 136 more rowsAquestes dades representen cada observació (un barri mesurat per la seva població i la seva renda) en dues files diferents, de manera que si volem, per exemple, estimar un model de regressió de la renda familiar sobre la població, no podrem. Per això necessitarem que hi hagi una columna de POBLACIO i una columna de RFD (renda familiar disponible). Per això farem el contrari de pivot_longer(), que és pivot_wider():
barris.wider <- barris %>%
pivot_wider(names_from = MESURA, values_from = VALOR)
barris.wider## # A tibble: 73 × 4
## DTE BARRIS POBLACIO RFD
## <dbl> <chr> <dbl> <dbl>
## 1 2 10 Sant Antoni 38414 954
## 2 3 11 el Poble Sec 41138 666
## 3 3 12 la Marina del Prat Vermell 1069 619
## 4 3 13 la Marina de Port 30134 744
## 5 3 14 la Font de la Guatlla 1031 824
## 6 3 15 Hostafrancs 16062 779
## 7 3 16 la Bordeta 18519 734
## 8 3 17 Sants - Badal 2447 785
## 9 3 18 Sants 42568 844
## 10 4 19 les Corts 47635 1317
## # … with 63 more rowsEl procés de canvi és l’invers que amb pivot_longer(), com mostra la Figura \(\ref{fig:spread}\).
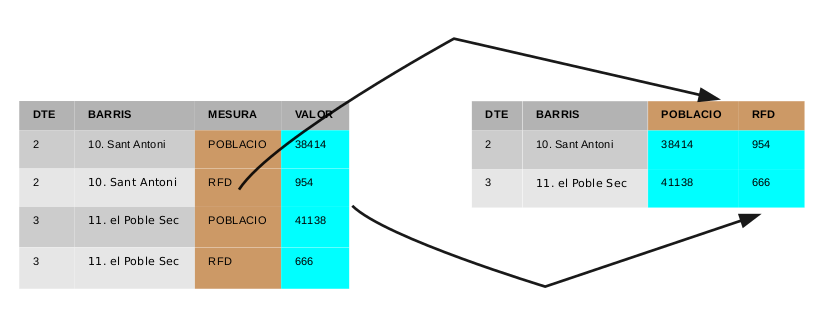
Conversió de dades llargues a dades amples.
En aquest cas, l’argument names_from és la variable que volem dividir en tantes columnes com valors tingui aquesta columna. En el nostre cas, la columna MESURA té els valors POBLACIO i RFD i, per tant, es crearan dues columnes amb aquests noms. L’argument values_from indica quina és la columna que conté els valors amb què s’hauran d’omplir aquestes columnes.
Ara ja podem fer el gràfic i estimar la recta de regresió per veure si hi ha relació entre població i renda familiar disponible:
## `geom_smooth()` using formula = 'y ~ x'## Warning: The following aesthetics were dropped during statistical transformation: label
## ℹ This can happen when ggplot fails to infer the correct grouping structure in the data.
## ℹ Did you forget to specify a `group` aesthetic or to convert a numerical variable into a factor?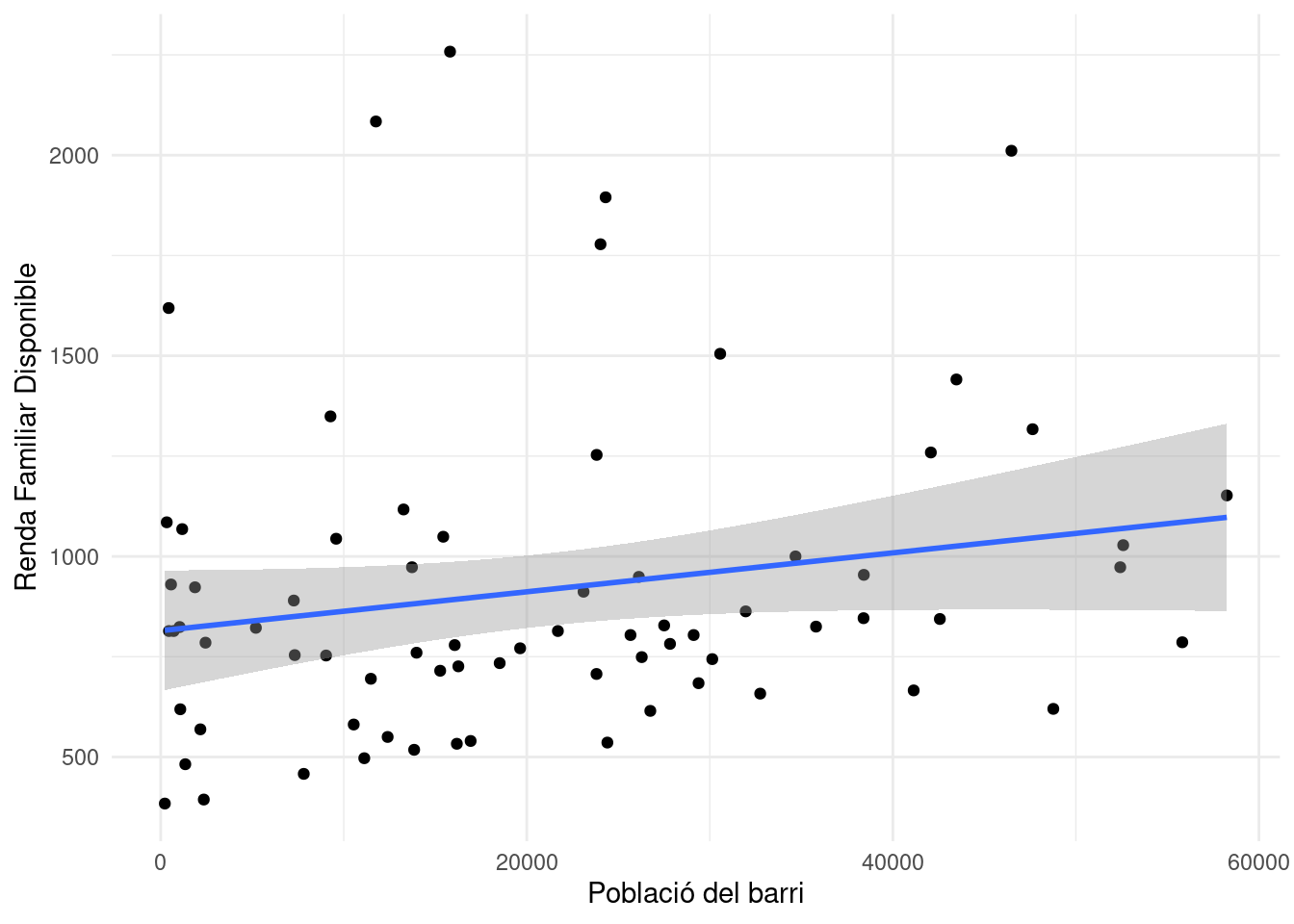
4.4 Separar amb separate() coses que estan unides
Tornem a fer servir el tibble anomenat rfd_g que hem creat abans. Fixem-nos que aquestes dades encara no compleixen ben bé els principis de tidy data: la variable BARRIS en realitat no representa una sola variable sinó dues: el codi de barri i el nom de barri. Per separar aquesta columna en dues farem servir la funció separate():
rfd.s <- rfd_g %>%
separate(
BARRIS,
into = c("codi_barri", "nom_barri"),
extra = "merge"
)
rfd.sL’argument, into estableix els noms de les variables en què volem dividir la columna BARRIS, mentre que l’argument extra estableix què cal fer quan hi ha massa peces en la columna sobre la que estem operant. En aquest cas, l’opció merge estableix que tot el que vingui després del separador entre el codi de barri i el nom de barri quedi inclòs en la segona variable (nom_barri). Fixeu-vos que no hem d’especificar el signe per on la funció separate() ha de separar el codi de barri del nom, perquè com que tots els valors tenen en comú que la separació és un punt, la funció ja entén que ho ha de fer així. Però ho podem especificar sense problema:
rfd.s <- rfd_g %>%
separate(
BARRIS,
into = c("codi_barri", "nom_barri"),
extra = "merge",
sep=". "
)
rfd.sAra el gràfic sobre l’evolució de la RFD per barris queda més bonic:
Eixample <- rfd.s %>% filter(DTE == 2)
ggplot(Eixample,aes(ANYS, RENDA, group = 1)) +
geom_line(size = 1) +
facet_wrap(~nom_barri) +
labs(
x="",
y="Renda Familiar Disponible"
)4.5 Unir amb unite() coses que estan separades
Pot passar, finalment, que necessitem unir els valors de dues columnes per formar-ne una de sola. En l’exemple que ens ocupa, imaginem que volem crear un identificador únic de barri que combini el codi de districte amb el codi de barri. Per fer-ho farem servir la funció unite(), que és la inversa de separate():
rfd.t <- rfd.s %>%
unite(
codi_unic,
DTE,
codi_barri,
sep = "_",
remove = FALSE
)
rfd.tEn aquest cas, l’argument sep estableix que entre els dos caràcters que volem combinar hi hagi un guió baix que els separi, i remove estableix que les dues variables origen no siguin eliminades de la base de dades.
Ja sabem com treure files (filter) o seleccionar columnes (select) d’un tibble, però sovint el que necessitem és fusionar bases de dades que tenim per separat. La clau per poder fusionar tibbles sempre és que entre els dos objectes que volem fusionar hi hagi com a mínim un element en comú. Aquest element pot ser el nom d’una columna o els noms de les files, en funció de si el que volem és obtenir un nou tibble que sigui més llarg (fusió vertical) o més ample (fusió horitzontal). Vegem-ho.
4.6 Fusió vertical de dades
El primer dels casos és l’ampliació vertical de les dades. Típicament, aquesta situació es produeix quan tenim dues bases de dades que expressen exactament el mateix (és a dir, tenen les mateixes variables) però les seves files tenen valors diferents. Imaginem que volem fer una anàlisi de comparació entre els assistents als actes d’un programa de foment de la lectura d’un ajuntament. Per exemple, obtenim dades d’assistència als actes de foment de la lectura de la xarxa de biblioteques de l’Ajuntament de Barcelona per al 2014 i 2015:
library(tidyverse)
ass14 <- read_csv("data/biblioteques-assistentsactivitatsfomentlectura_2014.csv")## Rows: 40 Columns: 9
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (5): Ambit, Titularitat, TipusEquipament, Equipament, Districte
## dbl (4): Any, Latitud, Longitud, AssistentsDifusioLectura
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.ass14## # A tibble: 40 × 9
## Any Ambit Titularitat Latitud Longitud TipusEquipament Equipament Distr…¹ Assis…²
## <dbl> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr> <dbl>
## 1 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.19 Biblioteques Biblioteca Barc… 01. Ci… 875
## 2 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Fran… 01. Ci… 1412
## 3 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Gòti… 01. Ci… 1165
## 4 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.17 Biblioteques Biblioteca Sant… 01. Ci… 2118
## 5 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.15 Biblioteques Biblioteca Esqu… 02. Ei… 2910
## 6 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Fort… 02. Ei… 1194
## 7 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.15 Biblioteques Biblioteca Joan… 02. Ei… 1942
## 8 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Sagr… 02. Ei… 3067
## 9 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.16 Biblioteques Biblioteca Sant… 02. Ei… 2255
## 10 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.17 Biblioteques Biblioteca Sofi… 02. Ei… 660
## # … with 30 more rows, and abbreviated variable names ¹Districte, ²AssistentsDifusioLecturaass15 <- read_csv("data/biblioteques-assistentsactivitatsfomentlectura_2015.csv")## Rows: 40 Columns: 9
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (5): Ambit, Titularitat, TipusEquipament, Equipament, Districte
## dbl (4): Any, Latitud, Longitud, AssistentsDifusioLectura
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.ass15## # A tibble: 40 × 9
## Any Ambit Titularitat Latitud Longitud TipusEquipament Equipament Distr…¹ Assis…²
## <dbl> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr> <dbl>
## 1 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.19 Biblioteques Biblioteca Barc… 01. Ci… 1585
## 2 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Fran… 01. Ci… 1984
## 3 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Gòti… 01. Ci… 1114
## 4 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.17 Biblioteques Biblioteca Sant… 01. Ci… 939
## 5 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.15 Biblioteques Biblioteca Esqu… 02. Ei… 3527
## 6 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Fort… 02. Ei… 775
## 7 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.15 Biblioteques Biblioteca Joan… 02. Ei… 285
## 8 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Sagr… 02. Ei… 3667
## 9 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.16 Biblioteques Biblioteca Sant… 02. Ei… 1247
## 10 2015 Lletres Consorci o fundació amb presència municipal 41.4 2.17 Biblioteques Biblioteca Sofi… 02. Ei… 1123
## # … with 30 more rows, and abbreviated variable names ¹Districte, ²AssistentsDifusioLecturaCom es pot observar, l’estructura dels dos tibbles és idèntica: els dos tenen 9 variables i aquestes variables expressen exactament el mateix. És a dir, l’Ajuntament ha volgut mesurar, en dos anys diferents, les mateixes característiques dels actes de foment de la lectura. Si pensem com volem que siguin les dades fusionades, com que hi ha coincidència completa en el nombre i el nom de les variables, el millor serà afegir les dades de 2015 a sota de les del 2014, de manera que el tibble resultant tindrà les observacions (files) corresponents a 2014 i les del 2015. Per fer-ho, R té una funció bàsica: bind_rows():
m <- bind_rows(ass14,ass15)
m## # A tibble: 80 × 9
## Any Ambit Titularitat Latitud Longitud TipusEquipament Equipament Distr…¹ Assis…²
## <dbl> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr> <dbl>
## 1 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.19 Biblioteques Biblioteca Barc… 01. Ci… 875
## 2 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Fran… 01. Ci… 1412
## 3 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Gòti… 01. Ci… 1165
## 4 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.17 Biblioteques Biblioteca Sant… 01. Ci… 2118
## 5 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.15 Biblioteques Biblioteca Esqu… 02. Ei… 2910
## 6 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Fort… 02. Ei… 1194
## 7 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.15 Biblioteques Biblioteca Joan… 02. Ei… 1942
## 8 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.18 Biblioteques Biblioteca Sagr… 02. Ei… 3067
## 9 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.16 Biblioteques Biblioteca Sant… 02. Ei… 2255
## 10 2014 Lletres Consorci o fundació amb presència municipal 41.4 2.17 Biblioteques Biblioteca Sofi… 02. Ei… 660
## # … with 70 more rows, and abbreviated variable names ¹Districte, ²AssistentsDifusioLecturaVeiem que el tibble resultant té r, nrow(m) files. No calia que els dos tibble tinguessin el mateix nombre de files, però sí com a mínim algunes columnes coincidents. En cas que hi hagi columnes que es troben en només un dels tibbles, bind_rows() mantindrà la columna i posarà NA en les files corresponents al tibble que no tenia aquesta columna. Vegem-ho amb un exemple inventat:
tbl1 <- tibble(a = c(1:5),
b = c(6:10))
tbl1## # A tibble: 5 × 2
## a b
## <int> <int>
## 1 1 6
## 2 2 7
## 3 3 8
## 4 4 9
## 5 5 10tbl2 <- tibble(a = c(11:15),
b = c(16:20),
c = LETTERS[1:5])
tbl2## # A tibble: 5 × 3
## a b c
## <int> <int> <chr>
## 1 11 16 A
## 2 12 17 B
## 3 13 18 C
## 4 14 19 D
## 5 15 20 Ebind_rows(tbl1,tbl2)## # A tibble: 10 × 3
## a b c
## <int> <int> <chr>
## 1 1 6 <NA>
## 2 2 7 <NA>
## 3 3 8 <NA>
## 4 4 9 <NA>
## 5 5 10 <NA>
## 6 11 16 A
## 7 12 17 B
## 8 13 18 C
## 9 14 19 D
## 10 15 20 E4.7 Fusió horitzontal de dades
La fusió horitzontal és una mica més complicada, només perquè requereix una mica més d’atenció per part nostra. Imaginem que hem fer servir dues bases de dades que estan separades i les volem fusionar en una sola base de dades.
Per exemple, necessitem relacionar l’activitat econòmica dels barris de Barcelona amb els preus de lloguer que es paguen en aquests barris. Comencem carregant les dades sobre locals i les dels lloguers:
locals_bcn <- read_csv("data/locals_bcn.csv",
locale = locale(encoding="ISO-8859-1"))## Rows: 73 Columns: 16
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (16): Codi_Barri, Activitats immobiliàries, Altres, Automoció, Ensenyament, Equipament personal, Equipaments culturals...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.locals_bcn## # A tibble: 73 × 16
## Codi_Barri Activit…¹ Altres Autom…² Ensen…³ Equip…⁴ Equip…⁵ Finan…⁶ Mante…⁷ Oci i…⁸ Param…⁹ Quoti…˟ Quoti…˟ Repar…˟ Resta…˟
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 12 642 1 54 208 66 40 NA 124 88 574 58 11 469
## 2 2 1 463 NA 16 484 46 33 NA 52 49 151 43 2 458
## 3 3 9 133 NA 15 19 10 8 NA 12 7 110 16 5 193
## 4 4 11 370 1 35 290 48 22 NA 35 66 254 40 4 333
## 5 5 18 711 6 28 35 22 21 2 26 36 148 42 36 181
## 6 6 39 873 13 41 175 23 57 8 92 72 344 81 57 369
## 7 7 52 1073 10 93 651 105 139 14 131 149 405 133 46 831
## 8 8 57 829 6 52 211 112 71 8 94 126 347 74 53 642
## 9 9 33 734 27 63 122 35 52 20 77 74 236 70 67 397
## 10 10 26 594 6 43 115 33 37 6 175 86 278 79 43 371
## # … with 63 more rows, 1 more variable: `Sanitat i assistència` <dbl>, and abbreviated variable names
## # ¹`Activitats immobiliàries`, ²Automoció, ³Ensenyament, ⁴`Equipament personal`, ⁵`Equipaments culturals i recreatius`,
## # ⁶`Finances i assegurances`, ⁷`Manteniment, neteja i producció`, ⁸`Oci i cultura`, ⁹`Parament de la llar`,
## # ˟`Quotidià alimentari`, ˟`Quotidià no alimentari`, ˟`Reparacions (Electrodomèstics i automòbils)`,
## # ˟`Restaurants, bars i hotels (Inclòs hostals, pensions i fondes)`lloguers <- read_csv("data/lloguers_2018_bcn.csv",
locale = locale(encoding="ISO-8859-1"))## Rows: 73 Columns: 6
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): Nom_Districte, Nom_Barri
## dbl (4): Any, Codi_Districte, Codi_Barri, mitjana_lloguer
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.lloguers## # A tibble: 73 × 6
## Any Codi_Districte Nom_Districte Codi_Barri Nom_Barri mitjana_lloguer
## <dbl> <dbl> <chr> <dbl> <chr> <dbl>
## 1 2018 1 Ciutat Vella 1 el Raval 823.
## 2 2018 1 Ciutat Vella 2 el Barri Gòtic 1023.
## 3 2018 1 Ciutat Vella 3 la Barceloneta 899.
## 4 2018 1 Ciutat Vella 4 Sant Pere, Santa Caterina i la Ribera 972.
## 5 2018 2 Eixample 5 el Fort Pienc 951.
## 6 2018 2 Eixample 6 la Sagrada Família 911.
## 7 2018 2 Eixample 7 la Dreta de l'Eixample 1253.
## 8 2018 2 Eixample 8 l'Antiga Esquerra de l'Eixample 1112.
## 9 2018 2 Eixample 9 la Nova Esquerra de l'Eixample 986.
## 10 2018 2 Eixample 10 Sant Antoni 934.
## # … with 63 more rowsSi volem fusionar aquestes dues bases de dades, no tindria cap sentit fer-ho en vertical, ja que el que volem és ampliar el nombre de columnes, no de files. És a dir, volem obtenir un nou tibble que, per a cada observació (cada fila, cada barri) ofereixi el preu mitjà de lloguer i el nombre de locals de cada tipus. Per tal que puguem dur a terme una fusió de dues bases de dades en direcció horitzontal, la condició indispensable és que hi hagi una columna que sigui idèntica en les dues bases de dades. Idèntica vol dir tres coses diferents: que les dues tinguin el mateix nom, que els seus valors siguin idèntics, i que les dues variables siguin del mateix tipus— és a dir, que les dues siguin numèriques, o factors, o de caràcter, etc.
Fixem-nos que en les nostres dades hi ha només una columna (Codi_Barri) que es troba en les dues bases de dades de manera idèntica (es diu igual, té els mateixos valors i en les dues bases de dades és numèrica), en aquest cas servint com a codi identificador únic de cada barri de Barcelona. En aquest cas, podem procedir a fusionar les dues bases de dades amb la funció full_join() i identificant quina és la columna que és comuna a totes dues bases de dades:
fusionades <- full_join(x=lloguers,
y=locals_bcn,
by="Codi_Barri")
fusionades## # A tibble: 73 × 21
## Any Codi_Districte Nom_D…¹ Codi_…² Nom_B…³ mitja…⁴ Activ…⁵ Altres Autom…⁶ Ensen…⁷ Equip…⁸ Equip…⁹ Finan…˟ Mante…˟ Oci i…˟
## <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2018 1 Ciutat… 1 el Rav… 823. 12 642 1 54 208 66 40 NA 124
## 2 2018 1 Ciutat… 2 el Bar… 1023. 1 463 NA 16 484 46 33 NA 52
## 3 2018 1 Ciutat… 3 la Bar… 899. 9 133 NA 15 19 10 8 NA 12
## 4 2018 1 Ciutat… 4 Sant P… 972. 11 370 1 35 290 48 22 NA 35
## 5 2018 2 Eixamp… 5 el For… 951. 18 711 6 28 35 22 21 2 26
## 6 2018 2 Eixamp… 6 la Sag… 911. 39 873 13 41 175 23 57 8 92
## 7 2018 2 Eixamp… 7 la Dre… 1253. 52 1073 10 93 651 105 139 14 131
## 8 2018 2 Eixamp… 8 l'Anti… 1112. 57 829 6 52 211 112 71 8 94
## 9 2018 2 Eixamp… 9 la Nov… 986. 33 734 27 63 122 35 52 20 77
## 10 2018 2 Eixamp… 10 Sant A… 934. 26 594 6 43 115 33 37 6 175
## # … with 63 more rows, 6 more variables: `Parament de la llar` <dbl>, `Quotidià alimentari` <dbl>,
## # `Quotidià no alimentari` <dbl>, `Reparacions (Electrodomèstics i automòbils)` <dbl>,
## # `Restaurants, bars i hotels (Inclòs hostals, pensions i fondes)` <dbl>, `Sanitat i assistència` <dbl>, and abbreviated
## # variable names ¹Nom_Districte, ²Codi_Barri, ³Nom_Barri, ⁴mitjana_lloguer, ⁵`Activitats immobiliàries`, ⁶Automoció,
## # ⁷Ensenyament, ⁸`Equipament personal`, ⁹`Equipaments culturals i recreatius`, ˟`Finances i assegurances`,
## # ˟`Manteniment, neteja i producció`, ˟`Oci i cultura`Hi ha funcions diferents per realitzar una fusió de bases de dades, i cadascuna d’elles respon a necessitats diferents.
full_join(): és la que acabem de fer servir; retorna totes les files i totes les columnes de x i de y. Quan no hi ha valors coincidents, afegeixNA.inner_join(): retorna totes les files de x quan tenen valors coincidents a y, i totes les columnes de x i y. Si hi ha múltiples coincidències entre x i y, retorna totes les combinacions de les coincidències.left_join(): retorna totes les files de x, i totes les columnes de x i y. Les files de x que no tenen coincidència a y tindran valorsNAen les noves columnes. Si hi ha múltiples coincidències entre x i y, retorna totes les combinacions de les coincidències.right_join(): igual queleft_join()però allà on posa x és y i viceversa.anti_join(): retorna totes les files de x que no tenen valors coincidents a y, preservant només les columnes de x.
Mireu aquest web per veure exemples de fusions diferents. Per veure aquests exemples, farem servir dues bases de dades molt petites sobre membres dels Beatles i els Rolling Stones i els instruments que toca cada membre:
band_members## # A tibble: 3 × 2
## name band
## <chr> <chr>
## 1 Mick Stones
## 2 John Beatles
## 3 Paul Beatlesband_instruments## # A tibble: 3 × 2
## name plays
## <chr> <chr>
## 1 John guitar
## 2 Paul bass
## 3 Keith guitar4.7.1 inner_join()
band_members %>% inner_join(band_instruments)## Joining, by = "name"## # A tibble: 2 × 3
## name band plays
## <chr> <chr> <chr>
## 1 John Beatles guitar
## 2 Paul Beatles bass4.7.2 left_join()
band_members %>% left_join(band_instruments)## Joining, by = "name"## # A tibble: 3 × 3
## name band plays
## <chr> <chr> <chr>
## 1 Mick Stones <NA>
## 2 John Beatles guitar
## 3 Paul Beatles bassband_instruments %>% left_join(band_members)## Joining, by = "name"## # A tibble: 3 × 3
## name plays band
## <chr> <chr> <chr>
## 1 John guitar Beatles
## 2 Paul bass Beatles
## 3 Keith guitar <NA>4.7.3 right_join()
band_members %>% right_join(band_instruments)## Joining, by = "name"## # A tibble: 3 × 3
## name band plays
## <chr> <chr> <chr>
## 1 John Beatles guitar
## 2 Paul Beatles bass
## 3 Keith <NA> guitarband_instruments %>% right_join(band_members)## Joining, by = "name"## # A tibble: 3 × 3
## name plays band
## <chr> <chr> <chr>
## 1 John guitar Beatles
## 2 Paul bass Beatles
## 3 Mick <NA> Stones4.8 Resolució de problemes de fusió
Posem-nos en un altre escenari: tenim dues bases de dades amb informació diferent sobre barris de Barcelona. En una d’elles tenim el preu del lloguer mitjà de cada barri (quatre trimestres) i a l’altra alguna informació demogràfica (població i població estrangera) sobre cada barri:
bcn.est <- read_csv("data/barris_poblacio.csv")## Rows: 73 Columns: 5
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): nombarri
## dbl (4): districte, barri, poblacio, estranger
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.bcn.est## # A tibble: 73 × 5
## districte barri nombarri poblacio estranger
## <dbl> <dbl> <chr> <dbl> <dbl>
## 1 1 1 el Raval 47617 27037
## 2 1 2 el Barri Gòtic 15269 7418
## 3 1 3 la Barceloneta 15036 5525
## 4 1 4 Sant Pere Santa Caterina i la Ribera 22305 10251
## 5 2 5 el Fort Pienc 31645 7847
## 6 2 6 la Sagrada Família 51347 12388
## 7 2 7 la Dreta de l'Eixample 43344 10555
## 8 2 8 l'Antiga Esquerra de l'Eixample 41696 10480
## 9 2 9 la Nova Esquerra de l'Eixample 57711 13087
## 10 2 10 Sant Antoni 38248 9998
## # … with 63 more rowsbcn.llog <- read_csv("data/lloguer_barris.csv",
locale = locale(encoding="ISO-8859-1",
decimal_mark=","))## Rows: 73 Columns: 6
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (5): barri, T1, T2, T3, T4
## dbl (1): districte
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.bcn.llog## # A tibble: 73 × 6
## districte barri T1 T2 T3 T4
## <dbl> <chr> <chr> <chr> <chr> <chr>
## 1 1 Raval 601.31 598.91 654 644.73
## 2 1 Barri Gòtic 756.68 771.13 773 831.13
## 3 1 Barceloneta 581.34 598.16 630 601.38
## 4 1 Sant Pere Santa Caterina i la Ribera 697.16 708.03 729 751.6
## 5 2 Fort Pienc 753.76 770.13 753 792.53
## 6 2 Sagrada Família 679.03 704.44 739 726.93
## 7 2 Dreta de l'Eixample 957.55 988.89 1052 1035.07
## 8 2 Antiga Esquerra de l'Eixample 859.64 906.14 926 941.58
## 9 2 Nova Esquerra de l'Eixample 766.18 766.85 807 789.76
## 10 2 Sant Antoni 740.41 746 798 772.11
## # … with 63 more rowsVolem obtenir un nou tibble que, per a cada observació (cada fila, cada barri) ofereixi el preu mitjà de lloguer en els quatre trimestres, la població total i la població estrangera. Aquí tenim un problema, perquè l’única columna identificadora potencial que és comú a totes dues bases de dades és el nom del barri (barri i nombarri).
El problema és que aquestes dues columnes no són ben bé idèntiques, perquè mentre en un cas els noms de barri van precedits d’un article, en l’altra base de dades no. Com que no són idèntiques, per tant, no les podem fer servier per fusionar les dades. L’única possibilitat que tenim és aprofitar que una de les bases de dades té una columna numèrica identificadora de barri (la columna barri de les dades bcn.est) i crear una columna idèntica en l’altra base de dades.
La variable identificadora del número de barri és simplement un nombre consecutiu de l’1 al 40, que identifica únicament cada barri. Crearem el mateix identificador al data frame que no el té i aleshores ja podrem utilitzar la funció full_join(). Cal vigilar, però, que la nova variable tingui el mateix nom en les dues bases de dades. A més, com que la variable “districte” també és coincident en les dues bases de dades, farem que només n’hi hagi una a la nova base de dades:
bcn.llog <- bcn.llog %>%
mutate(barriID=seq(1,nrow(bcn.llog),by=1))
bcn.est <- bcn.est %>%
mutate(barriID = barri) %>%
select(-barri)
m3 <- full_join(bcn.llog, bcn.est,
by = c("barriID","districte"))
m3## # A tibble: 73 × 10
## districte barri T1 T2 T3 T4 barriID nombarri pobla…¹ estra…²
## <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <dbl>
## 1 1 Raval 601.31 598.91 654 644.73 1 el Raval 47617 27037
## 2 1 Barri Gòtic 756.68 771.13 773 831.13 2 el Barri Gòtic 15269 7418
## 3 1 Barceloneta 581.34 598.16 630 601.38 3 la Barceloneta 15036 5525
## 4 1 Sant Pere Santa Caterina i la Ribera 697.16 708.03 729 751.6 4 Sant Pere Santa Cateri… 22305 10251
## 5 2 Fort Pienc 753.76 770.13 753 792.53 5 el Fort Pienc 31645 7847
## 6 2 Sagrada Família 679.03 704.44 739 726.93 6 la Sagrada Família 51347 12388
## 7 2 Dreta de l'Eixample 957.55 988.89 1052 1035.07 7 la Dreta de l'Eixample 43344 10555
## 8 2 Antiga Esquerra de l'Eixample 859.64 906.14 926 941.58 8 l'Antiga Esquerra de l… 41696 10480
## 9 2 Nova Esquerra de l'Eixample 766.18 766.85 807 789.76 9 la Nova Esquerra de l'… 57711 13087
## 10 2 Sant Antoni 740.41 746 798 772.11 10 Sant Antoni 38248 9998
## # … with 63 more rows, and abbreviated variable names ¹poblacio, ²estrangerHem especificat el número de barri i el de districte com a variables identificadores, de manera que ens assegurem que per tal que la fusió es faci correctament, hauran de coincidir tant el número de barri com el de districte. Veiem que la resta de variables que contenen valors diferents són afegides com a columnes al nou tibble.
4.9 Exercicis: Transformacions
Els següents exercicis els fareu amb les dades censals de Catalunya que hem treballat durant la sessió.
4.9.1 Transformació de dades
4.9.1.1 Exercici 1. A partir de les dades censals de Catalunya, feu el següent
Genereu un tibble que contingui només:
- Els municipis del Vallès Oriental
- Que l’any 2003 tinguessin una població immigrada inferior o igual al 3%
- Ordeneu-los pel seu percentatge de població immigrada, de major a menor
- Feu servir la pipe per encadenar les funcions.
4.9.1.2 Exercici 2. A partir de les dades censals de Catalunya, feu el següent:
- Creeu un subgrup de dades
dades_pibque contingui només els municipis per als quals hi ha dades de PIB/habitant - A
dades_pib, creeu una variable en què el PIB/habitant estigui expressat en euros (no en milers d’euros, com està ara) - Creeu un tibble
pib_altque contingui només els 10 municipis amb PIB/habitant més alt de Catalunya (ordre descendent) - Creeu un tibble
pib_baixque contingui només els 10 municipis amb PIB/habitant més baix de Catalunya (ordre descendent) - Creeu un tibble
pib_mamb el PIB/habitant mitjà de les comarques de Catalunya (ordre ascendent)
4.9.2 Transformació d’estructura
4.9.2.1 Exercici 1
Agafeu les dades sobre resultats electorals de les eleccions municipals de 2015 per barris de Barcelona i afegiu-hi una variable partit que contingui les sigles de tots els partits i una altra variable resultats que contingui el percentatge de vot que cada partit ha tret a cada barri.
4.9.2.2 Exercici 2
Agafeu les dades sobre ordres de protecció als partits judicials d’Espanya. Les ordres de protecció que s’incoen a un jutjat poden ser adoptases, denegades o inadmeses. La base de dades incou les següents variables:
- capital: nom del partit judicial
- partit_id: codi identificador del partit judicial
- tipus_resolucio: si les dades es refereixen a ordres incoades, inadmeses, adoptades o denegades
- quantitat: nombre total de resolucions de cada categoria
Feu que les categories de la variable tipus_resolucio siguin columnes independents. Després, creeu una nova variable p_denegades que indiqui el percentatge d’ordres denegades (sobre el total d’incoades) a cada partit judicial. Quins són els 10 partits judicials que deneguen més ordres?
Creeu un tibble que contingui només els partits judicials on s’admeten el 100% de les ordres incoades.
4.9.2.3 Exercici 3
Amb les dades censals sobre Catalunya CENSALS_CAT.csv, fes totes les operacions del tidyverse necessàries per tal d’obtenir 3 tibbles:
Un tibble
pob_comque contingui el nom de cada comarca i la seva població total cada any entre 1999 i 2009. Fes-ho de manera que tinguis 3 columnes: Comarca, Any i Població (per tant, han de ser dades llargues).Un tibble
cens_provque contingui el codi de província i el cens electoral total de cada província cada any entre 2002 i 2009.Un tibble
im_comque contingui el codi de província, codi de municipi, nom de cada comarca i el percentatge de població immigrada (sobre el total de població) de les comarques de Catalunya cada any entre 2000 i 2009.