Capítol 3 Transformació de les dades
3.1 Tidyverse
Els i les analistes dediquem el 80% del temps a netejar i preprar les dades per a l’anàlisi. Hi ha un seguit d’operacions sobres les dades que es repeteixen a casa anàlisi i que tenen a veure amb la forma que prenen les dades. Alguns dels processos més comuns són tractar missing values, detectar errors o tares en les dades o recodificar el valor de les variables segons les nostres necessitats.
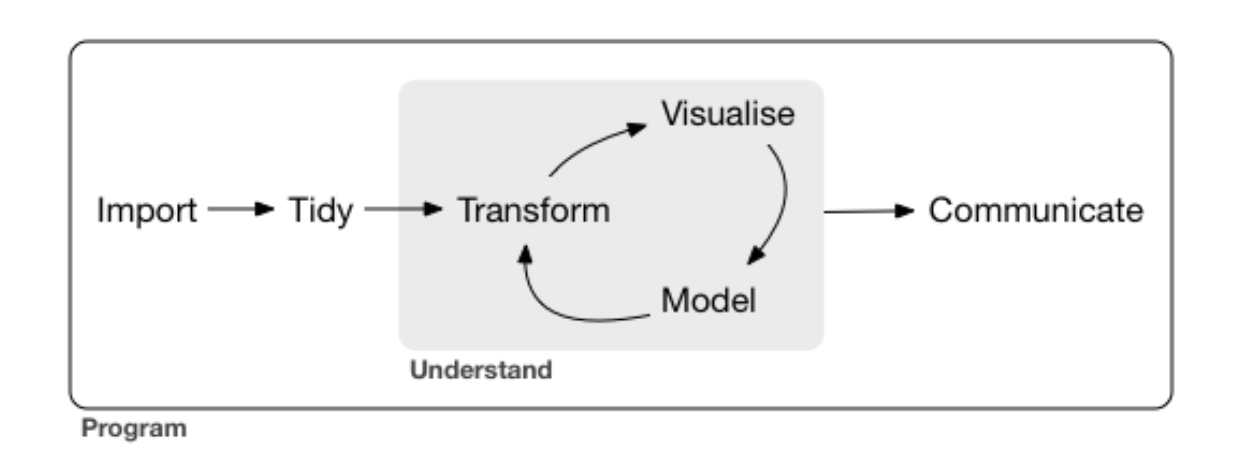
Procés d’anàlisi.
No existeix, però, una forma estàndard d’organitzar les dades compartida per les organitzacions o investigadors que treballen fent anàlisi de dades. És per això que H. Wickham entre d’altres han fet la porposta tidy (que han exemplificat a la Figura \(\ref{fig:proces}\). Es tracta d’un conjunt de bones pràctiques i principis a l’hora de treballar unes dades que s’ha traduit en un conjunt de paquets d’R. Aquest conjunt de paquets, que es mostren a la Figura \(\ref{fig:tidy}\), estan aplegats sota el nom de tidyverse i permeten realitzar les operacions més comunes, des de la importació fins a la visualització, de manera coherent.

Conjunt de paquets que formen tidyverse.
3.2 La gràcia es troba en l’estructura de les dades
Les dades que utilitzem habitualment en ciències socials són taules enormes. Habitualment les columnes tenen una etiqueta (nom) i les files de vegades també, encara que normalment només són un nombre. Per exemple, aquest és un format habitual de resultats electorals per municipi:
| JxSí | Cs | |
|---|---|---|
| Sentmenat | 39 | 16 |
| Polinyà | 24 | 27 |
| Gallifa | 65 | 7 |
Es tracta de tres files i tres columnes amb etiquetes en tots dos casos. També podem, però, organitzar les mateixes dades en dues files i tres columnes (també totes amb nom)
| Sentmenat | Polinyà | Gallifa | |
|---|---|---|---|
| JxSí | 39 | 24 | 65 |
| Cs | 16 | 27 | 7 |
Quants valors hi ha en aquestes taules?
Una base de dades rectangular és una col·lecció de valors. Els valor poden ser números (dades quantitatives) o cadenes de caràcters (dades qualitatives). Cadascun d’aquests valors pertany a una variable i a una observació. Una variable és un conjunt de valors que mesuren el mateix atribut subjacent per a totes les unitats com per exemple podria ser l’autoubicació ideològica, la identitat nacional subjectiva, etc. Una observació és el conjunt de valors mesurats de tots els atributs per a una mateixa unitat: un individu, un municipi, una elecció, un país, etc.
Les dades ben ordenades (tidy) són una forma estàndard de projectar el significat d’una base de dades rectangular sobre la seva estructura. Així, les dades estaran ben ordenades quan cada variable formi una columna, cada observació formi una fila i cada tipus d’unitat convencional formi una taula:
| municipi | candidatura | resultat |
|---|---|---|
| Sentmenat | JxSí | 39 |
| Polinyà | JxSí | 24 |
| Gallifa | JxSí | 65 |
| Sentmenat | Cs | 16 |
| Polinyà | Cs | 27 |
| Gallifa | Cs | 7 |
Ara sí, cada fila representa una observació (el resultat d’una candidatura en un municipi) i cada columna és només una variable. Aquesta es la forma d’organitzar les dades que anomenem tidy. Ens facilita l’anàlisi i el tractament de les dades a través de les funcions del paquet tidyverse.
Sempre que rebem unes dades noves hem d’assumir que no estaran ben ordenades ni netes i per tant fer un procés de revisió i transformació de la base de dades abans no començar a fer l’anàlisi pròpiament. Per exemple, un problema habitual és que els noms de les columnes no corresponen a variables diferents, sinó que són valors en si mateixos. Vegem-ho en dades reals. La taula següent mostra dades del preu de lloguer mitjà d’habitatges d’alguns barris de Barcelona de l’any 2015:
Les últimes quatre columnes són un problema: les columnes representen els quatre trimestres del 2015. Cada valor d’aquestes columnes representa el lloguer mitjà d’un barri en el trimestre corresponent. Així, el nom de la columna és en realitat una variable més: el trimestre. Per tant, cada fila no representa una sola obsevació, sinó quatre, contradient així els principis tidy quer hem anomenat abans.
Observem com serien les vuit primeres files de la versió ben ordenada d’aquestes mateixes dades:
Ara podem observar que com que el lloguer a cada barri es va mesurar quatre vegades (una per trimestre), apareix quatre vagades cada barri. Així, ara ja no tenim 73 files sinó \(73 * 4 = 292\)
Per acabar vegem un exemple de visualització possible un cop tenim les dades ben ordenades.
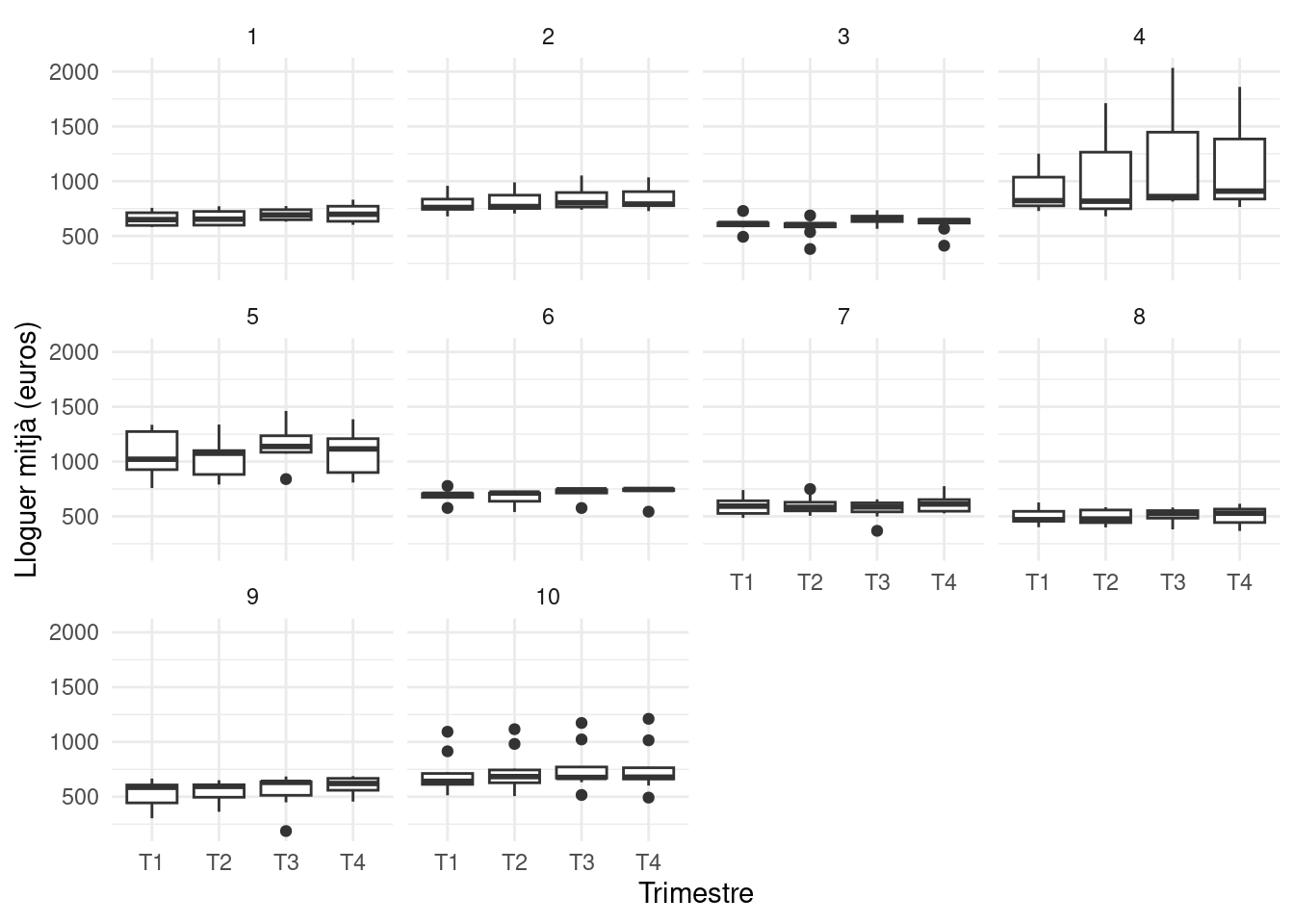
3.3 Transformació de les dades
3.3.1 Introducció
Si hi ha un principi general en l’anàlisi de dades que sigui vàlid, aquest és que no hi ha dues bases de dades iguals. Cada organització fa servir criteris diferents a l’hora d’emmagatzemar, organitzar i etiquetar les dades. Com a resultat d’això, la major part del temps d’un(a) analista de dades està dedicat a la neteja, organització i transformació de les dades. Per afegir una mica més de complicació a l’assumpte, la gran diversitat de models i gràfics amb què volem analitzar i comunicar les nostres anàlisis (amb R o qualsevol altre llenguatge) requereixen també formes d’organització de les dades diferents.
Per exemple, imaginem que ens demanen una cosa tan simple com que fem una anàlisi de l’evolució de la població immigrada a Catalunya i que per això ens passen les dades tal i com les ofereix l’IDESCAT:
censals <- read_delim("data/CENSALS_CAT.csv",
delim = "\t",
locale = locale(encoding= "ISO-8859-1"))## Rows: 946 Columns: 81
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (15): provincia, codi, municipi, Immig.2000, Immig.2001, Immig.2002, Immig.2003, Immig.2004, Immig.2005, Immig.2006, I...
## dbl (63): pob.1999, cens 1999, pob.2000, cens 2000, pob.2001, pob.2002, cens.2002, pob.2003, cens.2003, pob.2004, cens.200...
## num (1): PIBpm (per habitant, milers d'euros, 2006, per municipis amb més de 5000habitants o capitals de comarca)
## lgl (2): Immig.1999, cens.2001
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.censals## # A tibble: 946 × 81
## provincia codi municipi pob.1…¹ cens …² Immig…³ pob.2…⁴ cens …⁵ Immig…⁶ pob.2…⁷ cens.…⁸ Immig…⁹ pob.2…˟ cens.…˟ Immig…˟
## <chr> <chr> <chr> <dbl> <dbl> <lgl> <dbl> <dbl> <chr> <dbl> <lgl> <chr> <dbl> <dbl> <chr>
## 1 08 001 Abrera 7728 6261 NA 8177 6520 2,80 8454 NA 3,56 8823 6980 4,48
## 2 08 002 Aguilar de… 213 188 NA 213 180 0,47 208 NA 0,00 215 188 0,93
## 3 08 003 Alella 8176 6613 NA 8413 6680 3,47 8614 NA 4,30 8796 6874 5,34
## 4 08 004 Alpens 266 225 NA 264 215 3,41 274 NA 4,38 277 219 5,78
## 5 08 005 Ametlla de… 5294 4147 NA 5697 4270 4,46 5910 NA 5,20 6328 4719 6,16
## 6 08 006 Arenys de … 12345 10211 NA 12610 10388 3,78 12819 NA 4,69 13107 10426 6,50
## 7 08 007 Arenys de … 6037 5020 NA 6242 5124 2,37 6512 NA 3,15 6827 5510 4,03
## 8 08 008 Argençola 195 185 NA 196 184 0,51 188 NA 0,53 195 182 1,03
## 9 08 009 Argentona 9213 7612 NA 9482 7682 1,29 9791 NA 1,69 10056 8090 2,43
## 10 08 010 Artés 4293 3613 NA 4368 3598 0,64 4443 NA 1,06 4552 3692 1,93
## # … with 936 more rows, 66 more variables: pob.2003 <dbl>, cens.2003 <dbl>, Immig.2003 <chr>, pob.2004 <dbl>,
## # cens.2004 <dbl>, Immig.2004 <chr>, pob.2005 <dbl>, cens.2005 <dbl>, Immig.2005 <chr>, pob.2006 <dbl>, cens.2006 <dbl>,
## # Immig.2006 <chr>, pob.2007 <dbl>, cens.2007 <dbl>, Immig.2007 <chr>, pob.2008 <dbl>, cens.2008 <dbl>, Immig.2008 <chr>,
## # pob.2009 <dbl>, cens.2009 <dbl>, Immig.2009 <chr>, `Codi Comarca` <dbl>, Comarca <chr>,
## # `Població, 2000. 0 a 14 anys` <dbl>, `Població, 2000. 15 a 64 anys` <dbl>, `Població, 2000. 65 anys i més` <dbl>,
## # `Població, 2001. 0 a 14 anys` <dbl>, `Població, 2001. 15 a 64 anys` <dbl>, `Població, 2001. 65 anys i més` <dbl>,
## # `Població, 2002. 0 a 14 anys` <dbl>, `Població, 2002. 15 a 64 anys` <dbl>, `Població, 2002. 65 anys i més` <dbl>, …Tenint en compte l’estructura de les dades, si volem treure algun profit d’aquesta anàlisi hi ha tot un conjunt d’operacions que haurem de fer amb aquestes dades abans de començar a analitzar-les. Exemples de tasques que haurem de dur a terme són:
- Seleccionar només les variables que ens siguin d’utilitat
- Reorganitzar les dades de tal manera que puguem representar i analitzar l’evolució temporal del fenomen d’interès: la població immigrada
- Les dades estan municipi per municipi, però potser les volem resumir per província o comarca
- Un cop tinguem les dades que ens interessen, potser les voldrem ordenar segons els valors d’alguna columna
Fixem-nos que aquestes són tasques molt diferents entre elles. Mentre que les tasques (1) i (4) tracten només de filtrar i ordenar les dades sense canviar-ne l’estructura, la tasca (2) requereix canviar la forma mateixa en què les dades estan organitzades. Finalment, la tasca (3) tracta de crear noves variables que resumeixin alguns valors que ens siguin d’interès. Com heu vist al llarg del curs fins ara, aquestes quatre tasques requereixen la utilització de tasques i funcions ben diferents, sovint amb estils de codi també diferents. Això fa augmentar les probabilitats d’error en l’anàlisi. L’anàlisi de dades ha de ser prou ordenada com perquè puguem dur a terme aquestes tasques de forma ràpida, eficient i, sobretot, el més lliure d’errors com sigui possible.
Arrel del desenvolupament de l’anomenat tidyverse, totes aquestes tasques es poden dur a terme sota el mateix marc de programació amb R, és a dir, fent servir un estil de codi igual en totes elles. En la següent secció explorarem les 6 funcions bàsiques de transformació de dades del tidyverse. Després, veurem les 4 funcions bàsiques del tidyverse per canviar l’estructura d’unes dades. Emmig de tot això, aprendrem a enllaçar unes tasques amb altres de forma que amb una sola execució de codi puguem fer tots els canvis en les dades de cop.
Les sis funcions bàsiques de transformació de les dades del tidyverse són:
- Seleccionar variables cridant-les pel seu nom (
select()) - Seleccionar observacions segons els seus valors (
filter()) - Reordenar les files d’un data.frame (
arrange()) - Crear noves variables a partir d’executar funcions sobre variables existents (
mutate()) - Agrupar les dades segons els valors d’algun factor per tal de resumir-les (
group_by()) - Resumir els valors d’alguna variable a partir de l’agrupació per algun factor (
summarise())
Per veure com funcionen aquestes funcions, tornem a les dades de l’IDESCAT sobre la població immigrada als municipis de Catalunya. Carreguem les dades.
censals <- read_delim("data/CENSALS_CAT.csv",
delim = "\t",
locale = locale(encoding= "ISO-8859-1",
decimal_mark = ","))## Rows: 946 Columns: 81
## ── Column specification ──────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (4): provincia, codi, municipi, Comarca
## dbl (75): pob.1999, cens 1999, pob.2000, cens 2000, Immig.2000, pob.2001, Immig.2001, pob.2002, cens.2002, Immig.2002, pob...
## lgl (2): Immig.1999, cens.2001
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Imaginem que l’objectiu per ara és obtenir informació sobre la distribució de la població immigrada a Catalunya l’any 2000. Volem acabar presentant taules i gràfics sobre els municipis amb més i menys població immigrada, així com també presentar dades per províncies i comarques. Fem un pla d’anàlisi que inclou les següents tasques:
- Seleccionar només les variables rellevants: dades de població del 2000, codi de província, codi i nom de municipi, codi i nom de comarca.
- Per a les taules de municipis, caldrà filtrar i ordenar files segons els valors del percentatge de població immigrada.
- Per a les taules i gràfics per província i comarca, caldrà agrupar per província i comarca i calcular el percentatge de població immigrada pels valors d’aquests factors.
3.3.2 Seleccionar
Si volem obtenir un data frame amb la població municipal (total i immigrada) de l’any 2000, província, codi de municipi, nom de municipi, codi de comarca i nom de comarca, ho farem amb la funció select() del tidyverse:
sub <- select(
censals,
provincia,
codi,
municipi,
pob.2000,
Immig.2000,
`Codi Comarca`,
Comarca
)
sub## # A tibble: 946 × 7
## provincia codi municipi pob.2000 Immig.2000 `Codi Comarca` Comarca
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr>
## 1 08 001 Abrera 8177 2.8 11 Baix Llobregat
## 2 08 002 Aguilar de Segarra 213 0.47 7 Bages
## 3 08 003 Alella 8413 3.47 21 Maresme
## 4 08 004 Alpens 264 3.41 24 Osona
## 5 08 005 Ametlla del Vallès (L') 5697 4.46 41 Vallès Oriental
## 6 08 006 Arenys de Mar 12610 3.78 21 Maresme
## 7 08 007 Arenys de Munt 6242 2.37 21 Maresme
## 8 08 008 Argençola 196 0.51 6 Anoia
## 9 08 009 Argentona 9482 1.29 21 Maresme
## 10 08 010 Artés 4368 0.64 7 Bages
## # … with 936 more rowsFixeu-vos que en el món tidyverse els noms de les variables es poden introduir directament, és a dir, sense cometes. Només hi ha una excepció, que és quan els noms de les variables contenen espais entre paraules. Per exemple, el nom de la variable Codi Comarca l’hem posat entre dos accents oberts, ja que es tracta d’un nom que conté un espai entre dues paraules.
Un cop tenim les dades que volem, si hi ha alguna variable que ens sobra i la volem eliminar de la base de dades, farem servir el signe negatiu \((-)\) per designar la variable que volem eliminar:
sub <- select(sub,
-Comarca)
sub## # A tibble: 946 × 6
## provincia codi municipi pob.2000 Immig.2000 `Codi Comarca`
## <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 08 001 Abrera 8177 2.8 11
## 2 08 002 Aguilar de Segarra 213 0.47 7
## 3 08 003 Alella 8413 3.47 21
## 4 08 004 Alpens 264 3.41 24
## 5 08 005 Ametlla del Vallès (L') 5697 4.46 41
## 6 08 006 Arenys de Mar 12610 3.78 21
## 7 08 007 Arenys de Munt 6242 2.37 21
## 8 08 008 Argençola 196 0.51 6
## 9 08 009 Argentona 9482 1.29 21
## 10 08 010 Artés 4368 0.64 7
## # … with 936 more rowsEl codi que hem fet servir, però, encara pot ser més eficient. Fixem-nos que al tibble original, les variables provincia, codi i municipi són consecutives. En aquest cas, la funció select() admet que li diguem que seleccioni totes les variables que es troben entre dues variables, mitjançant el símbol “:”:
sub <- select(
censals,
provincia:municipi,
pob.2000,
Immig.2000,
`Codi Comarca`,
Comarca
)
sub## # A tibble: 946 × 7
## provincia codi municipi pob.2000 Immig.2000 `Codi Comarca` Comarca
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr>
## 1 08 001 Abrera 8177 2.8 11 Baix Llobregat
## 2 08 002 Aguilar de Segarra 213 0.47 7 Bages
## 3 08 003 Alella 8413 3.47 21 Maresme
## 4 08 004 Alpens 264 3.41 24 Osona
## 5 08 005 Ametlla del Vallès (L') 5697 4.46 41 Vallès Oriental
## 6 08 006 Arenys de Mar 12610 3.78 21 Maresme
## 7 08 007 Arenys de Munt 6242 2.37 21 Maresme
## 8 08 008 Argençola 196 0.51 6 Anoia
## 9 08 009 Argentona 9482 1.29 21 Maresme
## 10 08 010 Artés 4368 0.64 7 Bages
## # … with 936 more rowsFinalment, en cas que les variables que ens interessen tinguin elements en els seus noms que es repeteixin al llarg de la base de dades, podem treure profit d’un parell de funcions que ens permeten seleccionar totes les variables que comencin (starts_with()) o acabin (ends_with()) d’una manera determinada. Per exemple, fixem-nos que hi ha un conjunt de variables que comencen per cens i n’hi ha una per a cada any. Si ens interessés seleccionar totes les variables que comencen per cens, faríem:
sub2 <- select(
censals,
starts_with("cens")
)
sub2## # A tibble: 946 × 11
## `cens 1999` `cens 2000` cens.2001 cens.2002 cens.2003 cens.2004 cens.2005 cens.2006 cens.2007 cens.2008 cens.2009
## <dbl> <dbl> <lgl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 6261 6520 NA 6980 7076 7294 7473 7750 8032 8201 8317
## 2 188 180 NA 188 178 195 193 201 196 195 203
## 3 6613 6680 NA 6874 6696 6687 6719 6715 6763 6842 6884
## 4 225 215 NA 219 227 225 223 234 236 236 234
## 5 4147 4270 NA 4719 4863 5112 5223 5289 5387 5526 5603
## 6 10211 10388 NA 10426 10372 10418 10501 10538 10615 10735 10767
## 7 5020 5124 NA 5510 5453 5622 5686 5811 5922 6054 6136
## 8 185 184 NA 182 194 196 195 190 196 192 192
## 9 7612 7682 NA 8090 8167 8356 8489 8583 8721 8685 8810
## 10 3613 3598 NA 3692 3780 3848 3892 3930 3950 3967 4040
## # … with 936 more rows3.3.3 Filtrar i ordenar
Un cop tenim les dades que volem, ens pot interessar filtrar les observacions a partir d’alguna condició o bé ordenar les observacions segons algun altre criteri. Per exemple, si continuem amb les dades resultants de l’exercici anterior, el primer que volem fer és tenir una idea dels municipis on hi ha més i menys percentatge de població immigrada. Per fer-ho, crearem 2 subgrups de dades que continguin els municipis a partir d’un 15% de població immigrada i els que en tinguin un 0.5% o menys, per poder-ne fer un gràfic o una taula. Per això farem servir les funcions filter() (per filtrar observacions) i arrange() (per ordenar observacions).
Per crear un subgrup de dades amb els municipis amb més d’un 15% de població immigrada, amb les funcions filter() i arrange() ho podem fer:
df.mes <- filter(sub, Immig.2000 >= 15)
df.mes <- arrange(df.mes, Immig.2000)
df.mes## # A tibble: 7 × 7
## provincia codi municipi pob.2000 Immig.2000 `Codi Comarca` Comarca
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr>
## 1 08 199 Sant Bartomeu del Grau 1150 15.0 24 Osona
## 2 17 152 Roses 12857 15.2 2 Alt Empordà
## 3 17 178 Sant Pere Pescador 1428 17.0 2 Alt Empordà
## 4 17 120 Palau-saverdera 931 17.9 2 Alt Empordà
## 5 17 154 Sales de Llierca 89 19.1 19 Garrotxa
## 6 17 128 Pau 417 22.1 2 Alt Empordà
## 7 17 047 Castelló d'Empúries 6266 31.4 2 Alt EmpordàSi volguéssim que l’ordenació fos descendent, hauríem de fer servir la funció desc() dins d’arrange():
df.mes <- arrange(df.mes, desc(Immig.2000))
df.mes## # A tibble: 7 × 7
## provincia codi municipi pob.2000 Immig.2000 `Codi Comarca` Comarca
## <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr>
## 1 17 047 Castelló d'Empúries 6266 31.4 2 Alt Empordà
## 2 17 128 Pau 417 22.1 2 Alt Empordà
## 3 17 154 Sales de Llierca 89 19.1 19 Garrotxa
## 4 17 120 Palau-saverdera 931 17.9 2 Alt Empordà
## 5 17 178 Sant Pere Pescador 1428 17.0 2 Alt Empordà
## 6 17 152 Roses 12857 15.2 2 Alt Empordà
## 7 08 199 Sant Bartomeu del Grau 1150 15.0 24 Osona3.3.4 Filtrar per saber si hi ha NA a les observacions
Una de les coses més importants que cal saber de les nostres dades és fins a quin punt són completes o, el que és el mateix, si hi ha cel·les buides (és a dir, NA). En moltes ocasions, l’existència de cel·les buides entorpeix l’anàlisi i, per tant, és habitual que abans de posar-nos a fer càlculs eliminem les observacions d’una variable que no contenen dades.
Per eliminar les files que en la variable que ens interessa no tenen observacions (és a dir, que són NA), farem servir la funció drop_na(). Per exemple, si volem fer un subgrup de dades sobre població immigrada dels municipis per a l’any 2002, primer seleccionem les variables que ens interessen i després eliminem les files que no contenen observacions per aquesta variable:
sub <- select(censals,municipi, Immig.2002)
sub <- drop_na(sub,Immig.2002)3.3.5 La pipe per fer-ho tot més ràpid
Com que sovint volem fer més d’una operació concatenada (per exemple, seleccionar, filtrar i ordenar), podem també concatenar les tasques amb l’operador %>%, que en el món del tidyverse s’anomena pipe (pipe en anglès és una canonada, i el podem col·locar de forma ràpida amb les tecles Shift+Control M). Un avantatge d’això és que només hem de declarar les dades sobre les quals volem fer les operacions i després anar concatenant les funcions. En l’exemple anterior, faríem:
sub <- censals %>%
select(municipi, Immig.2002) %>%
drop_na(Immig.2002)O en l’exemple anterior a aquest, primer seleccionem, després filtrem i finalment ordenem:
df.mes <- censals %>%
select(provincia,
codi,
municipi,
starts_with("Immig.")) %>%
filter(Immig.2000 >= 15) %>%
arrange(desc(Immig.2000))
df.mes## # A tibble: 7 × 14
## provincia codi municipi Immig…¹ Immig…² Immig…³ Immig…⁴ Immig…⁵ Immig…⁶ Immig…⁷ Immig…⁸ Immig…⁹ Immig…˟ Immig…˟
## <chr> <chr> <chr> <lgl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 17 047 Castelló d'Empúries NA 31.4 36.0 40.0 42.8 36.4 42.9 45.6 46.8 49.9 50.9
## 2 17 128 Pau NA 22.1 22.5 27.1 29.3 25.3 29.8 34.3 35.0 36.4 35.8
## 3 17 154 Sales de Llierca NA 19.1 18.7 17.2 19.3 18.5 18.0 19.5 21.8 21.2 22.0
## 4 17 120 Palau-saverdera NA 17.9 20.6 24 26.4 22.7 30.2 30.7 31.6 32.9 34.0
## 5 17 178 Sant Pere Pescador NA 17.0 22.1 24.7 26.2 26.0 31.5 32.3 33.7 37.0 37.6
## 6 17 152 Roses NA 15.2 18.2 20.9 23.8 22.2 25.4 30.0 32.4 35.9 37.3
## 7 08 199 Sant Bartomeu del G… NA 15.0 19.0 20.1 19.5 18.3 18.3 15.8 13.6 14.5 14.9
## # … with abbreviated variable names ¹Immig.1999, ²Immig.2000, ³Immig.2001, ⁴Immig.2002, ⁵Immig.2003, ⁶Immig.2004,
## # ⁷Immig.2005, ⁸Immig.2006, ⁹Immig.2007, ˟Immig.2008, ˟Immig.20093.3.6 Crear noves variables
Un cop hem explorat les dades, i tenint en compte que voldrem després fer càlculs per comarques o províncies, fixem-nos que de cada municipi tenim el percentatge de població immigrada però no el nombre absolut d’aquesta població. Per tant, necessitem saber el nombre d’individus immigrats que hi ha a cada municipi, per després sumar-los per províncies i comarques. Com que només tenim el percentatge de població immigrant i el total de població, obtindrem el nombre absolut d’immigrants multiplicant la proporció d’immigrants per la població total del municipi. Amb tidyverse, tenim la funció mutate() que ens permet fer-ho de forma ben directa tot creant una variable nova al tibble amb el qual estem treballant. Fixeu-vos que primer creo el tibble que contingui només les variables d’interès i després faig servir mutate() per crear la variable nova:
sub <- censals %>%
select(municipi,
provincia,
Comarca,
Immig.2000,
pob.2000) %>%
mutate(pob.im=(Immig.2000 / 100) * pob.2000)
sub## # A tibble: 946 × 6
## municipi provincia Comarca Immig.2000 pob.2000 pob.im
## <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 Abrera 08 Baix Llobregat 2.8 8177 229.
## 2 Aguilar de Segarra 08 Bages 0.47 213 1.00
## 3 Alella 08 Maresme 3.47 8413 292.
## 4 Alpens 08 Osona 3.41 264 9.00
## 5 Ametlla del Vallès (L') 08 Vallès Oriental 4.46 5697 254.
## 6 Arenys de Mar 08 Maresme 3.78 12610 477.
## 7 Arenys de Munt 08 Maresme 2.37 6242 148.
## 8 Argençola 08 Anoia 0.51 196 1.00
## 9 Argentona 08 Maresme 1.29 9482 122.
## 10 Artés 08 Bages 0.64 4368 28.0
## # … with 936 more rowsCom que els percentatges de població immigrada tenen dos decimals, el nombre absolut de persones immigrades també em surt amb decimals. El que podem fer és fer servir la funció round() per arrodonir aquest nombre i que quedi sense decimals:
sub <- sub %>%
mutate(pob.im = round(pob.im,0))
sub## # A tibble: 946 × 6
## municipi provincia Comarca Immig.2000 pob.2000 pob.im
## <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 Abrera 08 Baix Llobregat 2.8 8177 229
## 2 Aguilar de Segarra 08 Bages 0.47 213 1
## 3 Alella 08 Maresme 3.47 8413 292
## 4 Alpens 08 Osona 3.41 264 9
## 5 Ametlla del Vallès (L') 08 Vallès Oriental 4.46 5697 254
## 6 Arenys de Mar 08 Maresme 3.78 12610 477
## 7 Arenys de Munt 08 Maresme 2.37 6242 148
## 8 Argençola 08 Anoia 0.51 196 1
## 9 Argentona 08 Maresme 1.29 9482 122
## 10 Artés 08 Bages 0.64 4368 28
## # … with 936 more rows3.3.7 Agrupar i resumir
Finalment, si volem calcular el percentatge de població immigrada de cada comarca haurem d’agrupar les dades agrupades de manera puguem sumar tota la població immigrada dels municipis de cada comarca i dividir-la per la suma de la població de tots els municipis de cada comarca. Per fer-ho, primer agruparem les dades amb group_by(), en què hi hem d’especificar la variable a partir del qual agrupem les dades (la comarca, en aquest cas), i summarise() per tal de fer els càlculs de les variables que vulguem.
Com que volem fer dues operacions concatenades (primer agrupar i, un cop amb les dades agrupades, fer els càlculs convenients), podem també concatenar les tasques amb l’operador %>% (Shift+Control M):
df.com <- sub %>%
group_by(Comarca) %>%
summarise(
pob = sum(pob.2000),
im = sum(pob.im)
) %>%
mutate(
perc_im = (im / pob) * 100
) %>%
arrange(desc(perc_im))
df.com## # A tibble: 41 × 4
## Comarca pob im perc_im
## <chr> <dbl> <dbl> <dbl>
## 1 Alt Empordà 101028 8809 8.72
## 2 Baix Empordà 103091 7618 7.39
## 3 Gironès 135482 8540 6.30
## 4 Selva 115648 6260 5.41
## 5 Pla de l'Estany 25130 1356 5.40
## 6 Segarra 18026 813 4.51
## 7 Baix Penedès 56843 2447 4.30
## 8 Urgell 31029 1318 4.25
## 9 Garraf 103467 4053 3.92
## 10 Osona 126853 4936 3.89
## # … with 31 more rowsL’estructura del codi que acabem d’executar es pot explicar com:
- Declarem primer les dades (
sub) per no haver-ho de fer més. - Connectem totes les operacions per ordre mitjançant la pipe (%>%)
- Fem servir la funció
summarise()per obtenir la suma de la població total i la de la població immigrant. - Creem una nova variable amb
mutate()que sigui el percentatge de població immigrant de cada comarca. - Ordenem les comarques pel seu percentatge de població immigrant amb
arrange()
La combinació entre group_by()i summarise() és molt útil per fer infinitat de coses. Per exemple, si seguim amb les dades anteriors, imaginem que tan sols volem obtenir un tibble amb el nombre de municipis que hi ha a cada comarca, podem combinar aquestes funcions amb la funció n() que fa un recompte de les observacions d’un grup:
n_municipis <- sub %>%
group_by(Comarca) %>%
summarise(N = n()) %>%
arrange(N)
n_municipis## # A tibble: 41 × 2
## Comarca N
## <chr> <int>
## 1 Alta Ribagorça 3
## 2 Barcelonès 5
## 3 Garraf 6
## 4 Vall d'Aran 9
## 5 Pla de l'Estany 11
## 6 Montsià 12
## 7 Terra Alta 12
## 8 Baix Ebre 14
## 9 Baix Penedès 14
## 10 Pallars Jussà 14
## # … with 31 more rows